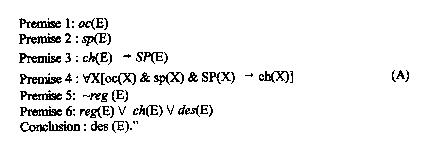
First posted on July 10, 2001. Updated August 10, 2003.
William A. Dembski is a very prolific writer whose literary production, while covering an extensive span of subjects, from history of philosophy to probability theory and from theology to information theory, seems to be all devoted to one idea to prove that the universe in general and life in particular are the results of a design by an unnamed intelligent mind.
In this article I shall discuss two of Dembski's books [1,2] as well as a number of his papers [3,4,5].
It seems that Dembski is one of the most prominent participants in the "intelligent design movement." Indeed, whereas another prolific writer, Phillip E. Johnson, who is a lawyer, has been proclaimed the leader of the "movement" in question (see A Militant Dilettante in Judgement of Science), Dembski's writing is much more sophisticated than the often very superficial even if rather eloquent diatribes by Johnson, and this makes Dembski arguably the most revered figure among his supporters and colleagues. Their articles and books are full of praise for Dembski's "mathematically rigorous" discourse. Here is just one example.
Professor of philosophy at the University of Texas Rob Koons wrote (quoted from the blurb on Dembski's book "Intelligent Design"): "William Dembski is the Isaac Newton of information theory, and since this is the Age of Information, that makes Dembski one of the most important thinkers of our time. His 'law of conservation of information' represents a revolutionary breakthrough."
Similar praise for Dembski's work can be found in the blurbs of his books and in many papers and books written by his supporters.
Here is one more quotation. Professor of biochemistry Michael J. Behe, (see Irreducible Contradiction) also often referred to as a pioneer in the modern revival of the intelligent design, in his foreword to Dembski's "Intelligent Design" wrote: "I expect that in the decades ahead we will see the contingent aspects of nature steadily shrink. And through all of this work we will make our judgment about design and contingency on the theoretical foundation of Bill Dembski's work."
Although I could easily quote many more examples of high acclaim bestowed on Dembski's work by his colleagues, it seems obvious that Dembski is rather universally being held in high esteem by his colleagues, who all seem to agree that his work is a revolutionary step in science, on a par with achievements of Newton. Dembski's admirers often stress that his work is the most scientifically rigorous one.
While Dembski's colleagues so highly admire his contribution to the "design theory," there have also been heard critical voices.
For example, in a book [6] professor of philosophy Robert T. Pennock offered a critical discussion of certain parts of Dembski's work. Some of Pennock's critique is directed at the so-called "explanatory filter," which has been suggested by Dembski as a versatile tool for establishing design. Other critical comments by Pennock relate to Dembski's thesis about the so-called "specified complex information." Pennock did not, though, review Dembski's work in a comprehensive way since his analysis of Dembski's ideas is only one of many topics discussed in the mentioned book.
Another book, in which we find a more detailed and systematic criticism of Dembski's work was published [7] by the professor of philosophy Del Ratzsch. The entirety of Ratzsch's writing makes it clear that he himself belongs to the camp of "design theorists." However, unlike most of his co-travelers, Ratzsch is usually logical and meticulous in his discourse. In an appendix to the mentioned book, Ratzsch subjects some parts of Dembski's work to a strong critique. Ratzsch's critical remarks relate almost exclusively to Dembski's "explanatory filter." In particular, Ratzsch convincingly illustrates the fallacy of Dembski's assertion that his "filter" does not produce "false positives," which is in itself sufficient to render the entire concept of that "filter" largely useless.
In a paper [8] Ellery Eells offered a critical analysis of Dembski's "The Design Inference," mainly of the parts devoted to what Dembski calls "magic number" of 1/2 as a universal threshold separating "small" and "not small" probabilities. Eells concludes that Dembski's theory is "not on the mark."
A detailed critical analysis of Dembski's theory was offered in a paper [9] by professors of philosophy Branden Fitelson, Christopher Stephens and Elliott Sober. This review discusses Dembski's discourse (mainly his explanatory filter) from philosophical and Bayesian viewpoints. This review does not seem to be addressed to laymen in philosophy and probability theory, but provides a number of intricate arguments revealing inconsistencies in Dembski's analysis.
Highly critical reviews [10,11] of Dembski's work were published by professor of ecology Massimo Pigliucci. The first review is of a rather general character, where Pigliucci does not delve into the intricacies of Dembski's discourse, mainly limiting his discussion by pointing to the menace to the genuine science from Dembski and the latter's cohorts in the so-called "intelligent design movement." The second review is more detailed. Here Pigliucci repudiates Dembski's assertion that science had unduly abandoned some of the Aristotle's four "causes." Pigliucci offers a classification of various types of design, interpreting this term in a broad sense, so that it encompasses four different versions of design, including what he calls "non-intelligent natural design." The latter, according to Pigliucci, does not require action of a conscious intelligent agent but may be, for example, the result of natural selection.
Other critical reviews of Dembski's work appeared on the Internet.
One of the well substantiated critical reviews of Dembski's "Intelligent Design" was suggested by the biologist Gert Korthof (see Was Darwin Wrong?). Korthof mainly concentrated on Demski's treatment of biological structures but also criticized inconsistencies in Dembski's treatment of information.
A rather detailed review of Dembski' work was written by Dr. Eli Chiprout of the IBM Research (this essay is temporarily available at http://members.cox.net/chiprout/DesignInference/Demski.htm).
As Chiprout has indicated, he shares Dembski's belief that the universe was created by an "intelligent designer." However, he says, this fact alone is not sufficient to accept uncritically Dembski's theory. Chiprout finds many faults in Dembski's theory. He concentrates mainly on the analysis of Dembski's so-called "explanatory filter," which many reviewers, both supporting and criticizing Dembski, seem to view as the central part of Dembski's work.
Several critical reviews of Dembski's work were offered by Wesley L. Elsberry (see Critiques and Reviews of the Work of William Dembski). In one of these reviews Elsberry points to discrepancies between Dembski's book "The Design Inference," and some of his other publications. One of the points discussed by Elsberry is the lack of discrimination in Dembski's discourse between a direct design by an intelligent agent and the design "by proxy." In Elsberry's another critical review, one of Elsberry's assertions is that the concept of design as defined by Dembski can also encompass natural selection.
One more paper arguing against Dembski was posted by Thomas D. Schneider (see Rebuttal to William A. Dembski's Posting). In that paper Schneider convincingly refutes some particular points of disagreement with Dembski, related to Schneider's computer simulation of evolution.
In Elsberry's website indicated above, there are links to some other reviews of Dembski's work, including rejoinders to a few replies from Dembski to his critics.
(Comment on February 19, 2002: I have recently learned about some critical reviews of Dembski's publication of which I did not know. I am listing here the links to these postings without comments, although I found these four pieces very interesting and offering various strong arguments against Dembski's position. 1) Richard Wein, What's Wrong with the Design Inference?. 2) Taner Edis, Darwin in Mind . 3) Victor J. Stenger, Messages from Heaven. 4). Matt Young, How to Evolve Specified Complexity by Natural Means).
While there are in the above listed papers and books certain points common for more than one reviewer, who happened sometimes to have noticed the same shortcomings of Dembski's discourse, one also finds in those papers a variety of approaches and viewpoints, all of which agree though that Dembski's work contains many weaknesses and inconsistencies.
While I largely agree with the critical comments by Pennock, Ratzsch, Chiprout, Elsberry, Eells, Korthof, Pigliucci, Schneider, and Fitelson-Stephens-Sober (except for some minor points some of which will be discussed later) I intend to offer in this article my own, more or less systematic, critical analysis of Dembski's theory, including not only his explanatory filter, but also his theoretical treatment of probability, complexity, information, and design. I intend to suggest some critical points which view Dembski's discourse from angles not utilized by the mentioned reviewers. I will try to make my critical analysis of Dembski's work as simple as it is reasonably possible, thus making it more or less comprehensible for non-experts. In some instances such an approach requires substantial simplifications without which a person having no extensive educational background in certain fields will not be able to comprehend the gist of the dispute. Whenever it will be impossible to avoid using some concepts or terms with which unprepared readers may be not familiar, I will try to explain these concepts or terms in plain words.
Before starting the detailed analysis of Dembski's work, let us briefly discuss Dembski's reaction to criticism. In an article printed in November 2000 issue of "The American Spectator" another proponent of "intelligent design" Fred Heeren quotes Dembski as saying: "I always learn more from my critics than from people who think I'm wonderful." Also, on page 13 in [5] Dembski says: "How can a scientist keep from descending into dogmatism? The only way I know is to look oneself squarely in the mirror and continually affirm: 'I may be wrong...' and mean it." This seems to be a good advice. However, reviewing Dembski's publications shows that the quoted statement as well as that quoted by Heeren must be taken with a grain of salt, because Dembski does not seem to follow his own advice. As mentioned, since his books were published, a number of highly critical reviews of them have appeared, including those from some people (like Ratzsch and Chiprout) who share Dembski's adherence to intelligent design.
The reaction from Dembski to the criticism seems to have been rather limited. From the material posted in the above mentioned Elsberry's website we can infer that Dembski has exchanged a few rejoinders with some of his opponents, including Schneider and Elsberry. He has posted a reply to Pennock. All that Dembski deigned to discuss in that brief piece, was Pennock's replacement of a single word ("evolutionists" instead of "evolution") in a quotation from Dembski, while ignoring the essence of Pennock's critical remarks regarding Dembski's publications. In a paper [5] Dembski allocated three full pages (pp 17-19) to an attack on Pennock. Almost all this criticism addressed a single paragraph in Pennock's book, in which Pennock did not mention either Dembski or the latter's writing. However, Dembski, again, ignored in his paper Pennock's criticism of Dembski's theory. In a posting, How Not to Analyze Design, Dembski replied to Eells, but his reply essentially boiled down to the assertion that Eells simply did not understand Dembski's fine theory. Dembski's public reply to Fitelson et al seems to have been limited to a single sentence at the end of his reply to Eells. (As indicated by Pigliucci and Fitelson et al, they received from Dembski private messages in reply to their criticism.) On the other hand, Dembski continues publishing the same arguments time and time again, often repeating verbatim his earlier publications, showing no sign of having paid any attention to and being seemingly unperturbed by the criticism from which he supposedly learns so much.
Dembski is obviously a well educated man of many talents, who, in my view, was led astray by his desire to promptly develop a neat theory of design, which would support his preconceived views and beliefs. Instead of following the logic of an objective analysis, he attempted to squeeze the enormous variability of real situations into the Procrustean couch of a one-dimensional theory. The real world however rarely fits a neat scheme.
Almost at the very beginning of "The Design Inference" [1] we discover a peculiar feature of Dembski's discourse. Its succinct expression is given in the following statement (page 9): "Design therefore constitutes a logical rather than causal category."
What is the meaning of that statement? If design is disconnected from any causal history, it seems to mean that Dembski's concept is that of a design without a designer.
Indeed, the quoted assertion is preceded (on page 8) by the following statement: "Although a design inference is often the occasion for inferring an intelligent agent... as a pattern of inference the design inference is not tied to any doctrine of intelligent agency." Note the word often in that quotation. Whatever interpretation of the quoted assertion one may prefer, often certainly does not mean always. It is hard to read that quotation other than an assertion that at least in some cases design does not imply a designer.
For centuries, the battle cry of the intelligent design proponents was "If there is design, there must be a designer." The proponents of the intelligent design viewed that slogan as logically unassailable. Now the new champion of intelligent design Dembski announces that the hypothesis of a designer is not necessary.
My interpretation of Dembski's assertion finds confirmation in his other statements. On the same page 9, he writes: "Thus, even though a design inference is frequently the first step toward identifying an intelligent agent, design as inferred from design inference does not entail an intelligent agent."
I submit that the design inference, whether according to Dembski, or by any other means, is aimed at distinguishing events that are designed by an intelligent agent from events that occurred without such an agent. Design inference is really interesting only if it is inference to a designer, either human, alien, or supernatural. (In order to stay within the framework of Dembski's concepts, I am not mentioning here the very interesting questions about "design" stemming either from artificial intelligence or from natural processes - as the latter was discussed by Pigliucci and Elsberry.)
The reason for Dembski's approach may be his desire to avoid accusations that "design theory" is just a disguised religion. However, to claim that design has meaning without a designer can hardly sound credible either to proponents or to opponents of the intelligent design hypothesis.
Having made his statement that separates design inference from inference to a designer, Dembski sometimes seems to forget about it. Here and there in his books and papers, he sometimes surreptitiously and sometimes quite openly squeezes in the idea of a designer who is behind the design. Actually, just two pages after Dembski's quoted claim that design does not necessarily imply an intelligent agent, Dembski seems to have forgotten this claim. He discusses an example of an election fraud committed by one Nicholas Caputo. As we will discuss later in detail, Dembski's method hinges on a triad of explanatory options which are, according to Dembski, regularity, chance and design. However, when discussing the Caputo case, Dembski presents this triad in the form regularity, chance and agency, i.e. replacing design with agency. The meaning of the term agency is unequivocally explained by Dembski in the next paragraph as an action "of a fully conscious intelligent agent" (page 11.) Hence, in Caputo's example, Dembski uses design and agency, as synonyms, where agency means actions of an intelligent agent.
This is just one example of inconsistencies found in many parts of Dembski's work.
3.
Dembski's explanatory filter
a) Description of the Explanatory Filter
Dembski suggests that his explanatory filter is a versatile tool for identifying design. He also maintains that the procedure encapsulated in his filter has been used routinely in many fields of human endeavors, without realizing it.
Dembski has published his description of the explanatory filter at least five times, in the above listed two books and three papers. The schematic presentations of his filter are slightly different in these five publications, but essentially they all are just variations of the same scheme.
There are several points underlying Dembski's scheme. One is that every event can be attributed to one of only three possible sources. The first such source Dembski calls necessity (in three of the published schemes of his filter) or regularity (in one of the published schemes) or law (in one more of the published schemes.) The second possible source of events is chance, and the third is design (sometimes also referred to as agency.) According to Dembski, these three possible sources of events cover all possibilities and are clearly distinguishable from each other. If, according to Dembski, an event can be attributed to law (regularity, necessity) then its causal connection to chance or design is unequivocally excluded. Likewise, if an event can be attributed to chance, a possibility of its causal connection to law and/or design is eliminated. Finally, if an event can be attributed to design, this automatically excludes its possible causal connection to chance and/or law. Indeed, here is a quotation from page 36 of Dembski's "The Design Inference": "To attribute an event to design is to say that it cannot reasonably be referred to either regularity or chance. Defining design as the set-theoretic complement of the disjunction regularity-or-chance guarantees that the three modes of explanation are mutually exclusive and exhaustive."
The second fundamental point of Dembski's scheme is the dominant role of probability of an event in the process of the filter's application.
The event to be analyzed is subjected to three tests, aimed at determining whether it can be attributed to regularity (law, necessity), chance, or design. Correspondingly, the filter comprises three so-called "nodes," i.e. three steps of testing. At each of the three steps there is a fork, whose one prong points out of the filter, and the other prong, to the next "node" or, in the case of the third "node," to the final conclusion about the causal antecedent of the event.
At the first "node" the choice is made between attributing the event in question either to law (regularity, necessity) or to absence of law. If law (regularity, necessity) is determined as the source of the event, the procedure stops at that step and the event is removed from the filter trough that prong of the fork leading out of the filter, while chance and design are eliminated as possible causal antecedents of that event. If, though, the law (regularity, necessity) is excluded as a causal antecedent, the event passes through the second prong of the fork, to the second "node."
At the second "node" the choice is made between either attributing the event unequivocally to chance, or, without eliminating the possibility of chance, also allowing for its possible attribution to design. If chance has been determined unequivocally as the causal antecedent, while the possibility of design is eliminated, the test stops at that step. If, though, neither chance nor design can be eliminated as possible causal antecedents, the event passes through the second prong of the fork to the third, ultimate "node." At this step, the final choice is made between attributing the event either to chance or to design, the two alternatives being, according to Dembski, mutually exclusive.
What are, according to Dembski, the criteria determining the choice between the two alternatives at each "node" of the filter? They are different for the first and the second "node," on the one hand, and for the third "node," on the other hand.
At the first and the second "nodes" there is, according to Dembski, one and only one criterion, which is the value of the event's probability. At the first "node," law (regularity, necessity) is determined as the causal antecedent of the event if, and only if the probability of that event is large. Dembski omits the question of what should be the lower bound on the probability in question in order for the event to qualify for being attributed to law (regularity, necessity.)
At the second "node," the only criterion for either unequivocally choosing chance as the causal antecedent of the event, or passing it to the third node, is again solely the value of the event's probability. If this probability is determined as being, in Dembski's terms, intermediate, the event is kicked out from the filter, being thus attributed to chance. Again, Dembski avoids indicating what is quantitatively the lower bound for the probability to be viewed as "intermediate." If, though, the probability of the event in question turns out to be "low" (whatever this term means quantitatively), the decision about the event's causal connection is postponed and the event passes through the second prong of the fork to the third "node."
The third "node" is the heart of Dembski's explanatory filter. Here the crucial choice is made between attributing the event to chance or to design. Unlike at the two preceding "nodes," where the sole criterion in use was the value of the event's probability, at the third node the criterion is two-fold. To qualify for being attributed to design, the event in question must: a) have a low probability and b) be "specified." Each of these two conditions is necessary, but neither of them alone is sufficient to attribute the event's origin to design. Only the two listed conditions together are both necessary and sufficient. If at least one of the two conditions is not met, the event is attributed to chance. If both conditions are met, the event is attributed to design.
Dembski's treatments of probability and of specification are different. In all five publications describing the explanatory filter, within the framework of that filter's scheme, probability is left without any detailed discussion (although probability is discussed in detail in a separate chapter in "The Design Inference," without explicit connection to the explanatory filter.) On the other hand, specification is discussed by Dembski in great detail.
As indicated in the preceding section, Dembski's criterion of design entails two necessary elements, one being the low probability of the event in question, and the other, the event's specification.
Dembski first explains that specification of an event means that it displays a pattern. One of the simple but telltale examples illustrating that concept is found in Michael Behe's foreword to Dembski's "Intelligent Design." Since Dembski never disowned the foreword in question, and, moreover, used himself elsewhere the same example, it seems safe to infer that he approves of Behe's presentation. Behe writes: "...we apprehend design in highly improbable (complex) events that also fit some independently identifiable pattern (specification.) For example, if we turned a corner and saw a couple of Scrabble letters on a table that spelled AN, we would not, just on that basis, be able to decide if they were purposely arranged... On the other hand, the probability of seeing some particular long sequence of Scrabble letters, such as NDEIRUABFDMOJHRINKE, is quite small (around one in a billion billion billion.) Nonetheless, if we saw that sequence lined up on a table, we would think little of it because it is not specified it matches no recognizable pattern. But if we saw a sequence of letters that read, say, METHINKSITISLIKEAWEASEL, we would easily conclude that the letters were intentionally arranged that way... It is a product of intelligent design."
Hence, Dembski's criterion of design is the combination of a very low probability with an identifiable (recognizable, specified) pattern.
Dembski spends a considerable effort to elaborate his requirement of a recognizable pattern (specification.) In order to serve as a specification, the pattern, according to Dembski, must meet an additional condition of "detachability." While Dembski offers a rather convoluted analysis of "detachability," he also provides a simple example clarifying that concept. He writes (page 17 in "The Design Inference"): "...suppose I walk down a dirt road and find some stones lying around. The configuration of stones says nothing to me. Given my background knowledge I can discover no pattern in the configuration that I could have formulated on my own without actually seeing the stones lying about as they do. I cannot detach the pattern of stones from the configuration they assume. I therefore have no reason to attribute the configuration to anything other than chance. But suppose next an astronomer travels this same road and looks at the same stones only to find that the configuration precisely matches some highly complex constellation. Given the astronomer's background knowledge, this pattern now becomes detachable."
From that example is evident that by detachability Dembski's actually means a subjective "recognizability" of the pattern in question. In order to decide that the pattern discerned in a low probability event is detachable, and hence serves as specification, i.e. points to design, we must be able to recognize that pattern as matching some already familiar image. For that to happen, we must have a certain background knowledge.
While the concept, as exemplified in the above quotation, seems simple enough, Dembski also provides a much more convoluted elaboration of detachability accompanied by its representation in a mathematical symbolism.
In order for an event to be detachable, teaches us Dembski, it must meet several conditions.
The first condition is "conditional independence" of the background knowledge. This condition means that the background knowledge which we utilize to recognize the pattern must not affect the probability of the event in question estimated on the assumption of it being produced by chance. In other words, the background knowledge must have no probabilistic implications for the event in question. For Dembski, the probability of an event and its specification are two independent categories, not affecting each other.
The second condition is "tractability." This term means, in Dembski's words (page 149 in "The Design Inference") that "by using I it should be possible to reconstruct D," where I is the background information and D is the pattern in question.
While conditional independence and tractability are, according to Dembski, the constituent parts of detachability, to qualify for specification the pattern must meet one more condition, referred to by Dembski as "delimitation." That concept is explained by Dembski as follows (page 152 in the same book): "...to say that D delimits E (or equivalently that E conforms to D) means that E entails D* (i.e. that the occurrence of E guarantees the occurrence of D*.)" In that definition, E means an event, D means the pattern and D* means "the event described by D" (page 151 in that book.)
Dembski's main idea has been succinctly expressed under the label of "Law of Small Probability," (page 48 in "The Design Inference") as follows: "Specified events of low probability do not occur by chance."
Now, having briefly described Dembski's concept of the explanatory filter, we can turn to the discussion of its weaknesses and inconsistencies
Before discussing in detail the inconsistencies in Dembski's explanatory filter theory, I wish to first comment on one striking feature of Dembski's writing, especially pronounced in his highly technical monograph "The Design Inference."
If the quality of a mathematical treatise were evaluated by the number of mathematical symbols, Dembski's book "The Design Inference" would qualify as a great achievement in mathematics. This may be one of the reasons why many of Dembski's colleagues in the so-called "intelligent design movement" so much admire his opus. They commonly praise the supposed great rigor of Dembski's mathematical analysis. It is interesting to note, though, that most such accolades stem from the writers who themselves do not seem to be mathematicians.
Reviewing all these extensive collections of mathematical expressions in Dembski's book reveals that only a few of them are anything more than a simple illustration of whatever Dembski states in plain words. Except for a few cases (of which some are not quite relevant to Dembski's thesis) his mathematical exercise does not either prove any new mathematical theorem or derive any new formula. Actually the removal of 80% of those formulas would hardly make much difference except for depriving Dembski's book of its mathematical appearance.
The use of mathematical language in science is discussed in detail at Science In the Eyes Of a Scientist. When a new mathematical theorem is proven, it advances the mathematics itself, thus possibly opening new vistas for additional applications. If a mathematical formula is derived in physics, or some technical science, or engineering, it compresses into easily comprehensible form certain essential relations between various data, which otherwise would be much harder to review and manipulate. This immensely facilitates some useful procedure. If, though, mathematical symbolism is used for the sake of symbolism itself, it does not advance the understanding of a subject, at best simply saving some space and time in the discussion of a subject, and at worst making the matter more obscure because of esoteric symbolism which requires a lengthy deciphering.
Actually Dembski's book "The Design Inference" contains little of genuine mathematics, but is full of "mathematism," this term denoting the use of mathematical symbolism as embellishment, often possibly only to create an impression of a scientific rigor of the discourse.
To illustrate my point, consider the following example. On page 48 of "The Design Inference" Dembski offers the following argument:
Premise 1: E has occurred.
Premise 2: E is specified.
Premise 3: If E is due to chance, then E has small probability.
Premise 4: Specified events of small probability do not occur by chance.
Premise 5: E is not due to regularity.
Premise 6: E is due either to a regularity, chance or design.
Conclusion: E is due to design.
(I am not yet discussing either merits or drawbacks of the above argument, since my goal at this point is simply to illustrate the "mathematism" employed by Dembski throughout his book.)
Next Dembski writes (page 49): "The validity of the preceding argument becomes clear once we recast it in symbolic form (note that E is a fixed event and that in Premise 4, X is a bound variable ranging over events):
The above argument, now rendered in a mathematically symbolic form, exactly reiterates the preceding plain-word rendition of the same argument. A question is: in what way does representing the same argument in a symbolic form make its validity clear? I submit that reiterating the above argument in a symbolic form adds nothing to its interpretation and does not at all make its validity more clear. This symbolic rendition sheds no additional light on the argument in question, neither supporting nor negating its validity. Moreover, this rendition in itself does not even save space or time since the symbols used in it require explanation in plain words. In order to make the symbolic rendition understandable, its author had to provide a glossary of symbols. Dembski must explain to readers (I am quoting from page 49) that
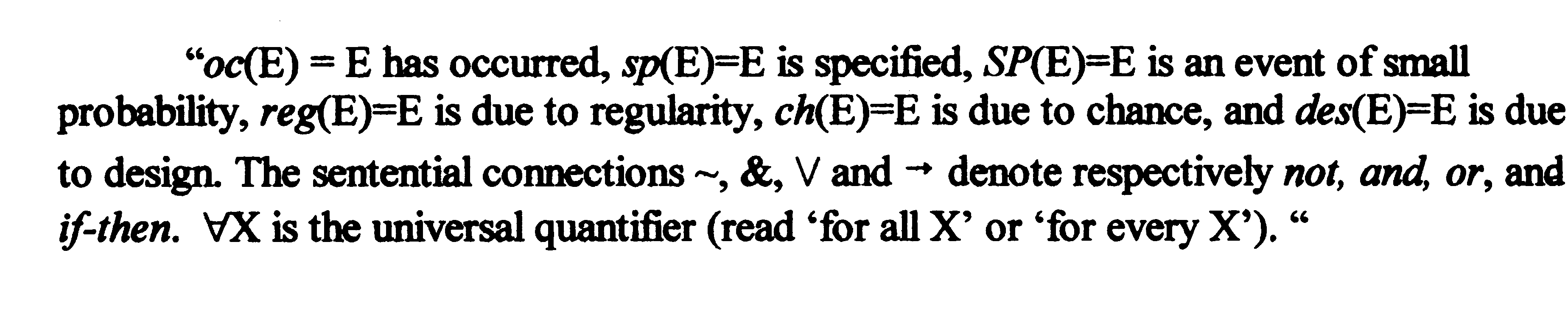
As can be seen, the symbolic rendition not only does not add anything of substance, it actually has no advantages over the preceding plain-word rendition even from the viewpoint of brevity. It seems to me that its only purpose was to impart on the discourse a rigorously-mathematical appearance.
Moreover, still not satisfied with the above symbolic rendition of his "design inference," Dembski offers several modifications of that rendition, gradually making its appearance more and more complex.
Throughout his book "The Design Inference" Dembski saturates his text with numerous combinations of mathematical symbols thus creating an impression of a sophisticated mathematical treatise. In my view, most of those combinations could be left out without doing any harm to his explanations.
I can envision a possible suspicion that my criticism of Dembski's extensive use of mathematical symbolism stems from my own discomfort with mathematics. I don't think this is the case. While I am a physicist rather than a mathematician, I enjoy mathematical treatment of various problems. I have derived hundreds of formulas which have been published in several hundreds of articles and monographs. They cover a rather wide range of topics. (For those skeptical of assertions not supported by direct references, here are just two examples of my published articles chock-full of formulas: 1. Mark Perakh, "Slot-type Field-Shaping Cell: Theory, Experiment and Application." Surface and Coatings Technology, 31, 409-426, 1987; 2. Mark Perakh, "Calculation of Spontaneous Macrostress in Deposits From Deformation of Substrates and Restoring (or Restraining) Factors." Surface Technology, 8, 265-309, 1979.) I have no objections to Dembski's extensive use of mathematical symbolism, which is his right and often looks quite attractive, but I don't think this extensive mathematism justifies viewing his discourse as mathematically rigorous. Many parts of that mathematical symbolism seem to serve no useful purpose.
I will discuss now a point, which, in my view, entails a rather general fault of the approach embodied in Dembski's Explanatory Filter.
Suggesting his explanatory filter as a versatile tool for discrimination between law, chance and design, Dembski bases the process of such discrimination on the evaluation of probabilities of events. One moves from one "node" of the filter to the next one according to the estimated value of the event's probability.
Dembski's entire chain of arguments presumes that probability is an independent category which may be estimated by itself without accounting for the possible cause of the event in question.
For example, on page 38 of "The Design Inference" we read: "Thus, if E happens to be an HP event, we stop and attribute E to a regularity." In this sentence E stands for "event" and HP for "high probability."
Actually we can't assert that "E happens to be an HP event," if we have not first assumed that it is due to law (regularity, necessity.) In fact, probability does not exist by itself, as an abstract concept, and can only be estimated by accounting for various types of information about the event in question. Dembski seems to realize that fact when he discusses probability in a chapter about probability but seems to forget about it when he turns to his explanatory filter.
According to Dembski, at the first "node" of his filter we attribute events to law (regularity, necessity) because their probability is high. I believe that the common procedure is opposite to his scheme: we conclude that the probability of an event is high, because it is due to law (regularity, necessity.)
Possibly Dembski's reversal of the normal order of inference in this case stems from his confusion of two very different procedures one of postulating a certain law (let us denote it procedure A) and the other of attributing a particular event to some law (procedure B.) Obviously, the procedure at the first "node" of Dembski's explanatory filter is of B type. Procedures of scientific induction (A type) which are common in scientific research are discussed in detail at Science In the Eyes Of a Scientist. The classical version of procedure A is conducted under the conditions of ceteris paribus (see the above reference).
Despite the superficial similarity between the procedure of scientific induction and Dembski's alleged attribution of an event to law because its probability is high, these two procedures are principally different. At the first "node" of Dembski's filter, we have to decide whether or not a particular event has to be attributed to a regularity, while in the procedure of a scientific induction we postulate a definite regularity after having observed multiple repetitions of occurrences of certain events. In the latter case the tentative conclusion of a researcher is that "under these particular conditions the probability of a certain event is very high." On the other hand, at the first "node" of Dembski's filter the conclusion, according to his scheme, has to be "the probability of that particular event is high, therefore it must be attributed to regularity."
However, we can't conclude that the probability of a particular event is high unless we know it is due to regularity. Assume that we observed a particular event a piece of metal Gallium in a vessel melted when the temperature reached about 302.5 K. Observing that event does not provide any clue regarding its probability. Unless we already know the law - the transition from solid to liquid in the case of pure Gallium, at atmospheric pressure, always occurs at about 302.5 K - we cannot assert that the observed event has a high probability and therefore has to be attributed to law. On the other hand, if we know the law pure Gallium under atmospheric pressure melts at about 302.5 K - then we can confidently attribute the observed event to a law, and hence to estimate its probability as being very high.
Even if an event has been observed many times, this in itself is not sufficient to assume that its probability is high. As discussed at Science In the Eyes Of a Scientist, there is a necessary intermediate step postulating that the observed repetition of the event was a manifestation of a law. It is not an uncommon situation in a scientific research when a repetition of a certain event is observed but nevertheless no assumption is made that a new law is at work.
In order to assign to an event a high probability first a law has to be accepted.
Likewise, at the second "node," according to Dembski, we attribute an event to chance because its probability is "intermediate." Again, I believe that the common procedure is just the opposite: we estimate the probability of a particular event assuming first that it is due to chance (see an example with a raffle described a little later.) Note that at the third "node" of the filter, Dembski himself suggests to estimate the probability of an event by first assuming that it is due to chance, which is contrary to the procedure he suggests for the second "node."
As can be seen from Dembski's own definition of probability (which will be discussed in detail in one of the subsequent sections) he defines probability as being conditioned "with respect to the background information." I believe that if Dembski has adopted a certain definition, he is supposed to stick to it throughout his discourse. However, when Dembski turns to his explanatory filter he seems to forget his own concept of probability.
Imagine that we estimate the probability of John Doe's winning in a raffle. Let us assume that there are one million tickets distributed in that raffle, each with the same chance of winning. What is our estimate of John Doe's probability of winning? Can we say unconditionally that the probability in question is one in a million? If we adopt Dembski's definition of probability, we can't say that. Based on his definition, we must say instead: "John Doe's probability of winning is one in a million upon the assumption that the drawing is random." In other words, the estimation of probability incorporates an assumption regarding the nature of the event in question, namely its being the result of chance. Accounting for all the relevant background information is necessary if we want to meet Dembski's definition of probability.
Imagine, though, that we have information about John Doe being in cahoots with the organizers of the raffle who have a record of earlier frauds. This background information must be incorporated in our estimate of probability. Upon the assumption that the new information obtains, the new estimate of probability of John Doe's winning is immensely higher than before. Based on the new information, we assume that John Doe's win is due to design (in this case, fraud), and that new assumption leads to a drastically increased estimate of the probability of his win.
The situation is different for the third node of Dembski's filter where the probability is first estimated upon the assumption of chance as the cause of the event, and then the situation is reconsidered accounting for the side information. The latter is though assumed not to affect the probability. I will discuss this assumption in subsequent sections.
It does not matter for the estimation of probability whether background information is actually available or is assumed for the sake of estimation. We estimate probability on the basis of a certain background information, either actually available, or assumed for the sake of estimation. Consciously or subconsciously, the assumption about the cause of the event is incorporated into the estimate of probability.
In particular, to conclude that an event is due to law, we have, according to Dembski, to first find that its probability is high. However, if we do not assume a priori that the event is due to law, so that we estimate its probability upon the assumption that it is due to chance, we will often arrive at a small probability which, according to Dembski, would point to either chance or design rather than to law. Here seems to be a vicious circle and to break out of it, there seems to be the only way to get out of the confines of Dembski's scheme.
In subsequent sections I will further elaborate on that thesis, both in a way of examples and through some more general notions.
Another weakness of Dembski's scheme seems to be that, while attributing each event to either law, or chance, or design, he fails to account for the taxonomy of events according to any other criteria. It seems rather obvious that there are whole classes of events for which it may be impossible to identify their causal antecedents as belonging to only one of the three distinctive categories.
Consider one of Dembski's favorite examples, that of an archery competition. If an archer shot an arrow and hit a target, it is, according to Dembski, a specified event which definitely must be attributed to design. In Dembski's scheme, design excludes both chance and law. Can we really exclude law as a causal antecedent of the event in question? I submit that the archer's success was the result not of design alone, but of a combination of design and law. Indeed, archer's skill manifests itself only in ensuring a certain velocity of the arrow at the moment it leaves the bow. This value of velocity is due to design. However, as soon as the arrow has separated from the bow, its further flight is governed by laws of mechanics. The specified event the perfect hit was due to both design and law. The arrow would not hit the target if any one of these two causal antecedents were absent. We simply cannot separate the design from law in this case, because in this case design operates through law and would be impossible without law. Therefore Dembski's scheme which artificially divorces law from design, viewing them as two completely independent explanatory categories, does not seem to jibe with reality. (Besides law, chance may also contribute to the occurrence of a hit; for example, an accidental gust of wind may affect the flight of the arrow.)
In the class of events exemplified by the archer's feat, law and design not only are not mutually exclusive but, on the contrary, are complementary causal factors.
Likewise, there is a whole class of events for which it is impossible to separate law from chance as causal antecedents. Here is an example. There is a machine used for training tennis players. It randomly hurls tennis balls toward a player. There may be a large number of balls flying every minute, and it is impossible to predict the exact direction of each next flying ball. Choose an area anywhere within the court, say, of one square meter. Assume a particular ball landed within that area. Is that event due to chance or law? If in the course of a certain period of time the total number of flying balls was, say, 1000, and, say, only 50 of those balls landed within the selected one square meter, I believe, in such a situation most of the observers will attribute the event in question to chance. In fact, though, chance only determines the initial velocity of each ball. Upon leaving the machine, the flight of the ball and hence the location of its landing are determined by laws of mechanics. In this case, chance operates through law, so the location of the ball's landing is determined by both chance and law. The event most reasonably has to be attributed to a combination of law and chance.
Hence, for certain classes of events Dembski's filter fails to deliver already at its first "node."
Furthermore, as statistical science shows, random events follow certain laws, therefore even if an event is viewed as random, it cannot be completely divorced from a (statistical) law which is instrumental in causing the event in question. For example, recall the so called Galton board which is a device demonstrating the normal (Gaussian) distribution of chance events. In this device, hundreds of small balls are placed in a hopper which has an opening in its bottom. Pulled by gravitation, the balls fall down one by one. On their way down, the balls encounter a grid of hexagonal baffles. At each baffle, each ball has the same probability of 1/2 to pass the baffle either on the latter's left or its right side. After passing several rows of baffles, the balls fall into a row of bins. Which ball happens to get into which bin, is determined by chance. However, regardless of the absolute sizes of the device or of its parts, the overall result is always the same: when a sufficiently large number of balls fill the bins, their distribution between the bins meets the normal (Gaussian) distribution. In this case, the situation is in a sense opposite to the case of the tennis balls: while for the tennis balls chance operated through law, now the law (Gaussian distribution) operates through chance.
In all those examples, law and chance or law and design are equally contributing causal antecedents of an event.
Moreover, if we review again the example with tennis balls, it easy to see that, since the machine that hurls the balls has been designed by a human intelligent agent (an engineer) the event in question may be viewed in a certain sense as a causal consequent of all three sources design, chance and law, whose contributions to the occurrence of the event cannot be separated from each other since each of them is necessary for the event to occur.
There are enormously many situations wherein regularity, design and chance are intertwined in various combinations, each contributing to varying degrees to the occurrence of events. Moreover, more than half a century after the formulation of principles of cybernetics, Dembski's scheme seems to be too simplistic in that it views the causal history of events as a one-directional straightforward process, thus ignoring feedbacks, conditional causes, superimposition of multiple causes of events, etc.
Therefore, in my view, Dembski's scheme based on the uncompromising demarcation between law, chance and design which are viewed as clearly separate causal categories, being always completely independent from each other, seems to be rather off the mark.
Now review what happens if an event passed to the second "node" of Dembski's filter. At this step, the probability of the event, which was found to be "not large" at the preceding step, is re-evaluated, to determine whether it is "intermediate" or "small." We know already that Dembski does not offer a definite quantitative criterion for classifying probability as either "intermediate," or "small." Of course, without such a criterion the procedure becomes quite uncertain, since what seems to be small for John may seem very large for Mary.
The more important objection to Dembski's scheme is, though, that, according to the above analysis, attributing an event to law or chance is normally not based on a prior estimate of probability, as Dembski suggests, but, on the contrary, probability can be estimated only after either law or chance have been determined as the event's causal antecedents. Therefore I submit that the first and the second "nodes" of his filter offer an unrealistic scenario and hence play no useful role for the design inference.
If any meaningful design inference takes place, all of it can only occur within the framework of the third "node" of the filter.
Of course, if that is the case, the filter loses its impressive appearance of a triad so neatly matching the three supposedly independent causes of events.
Assume, though, that we follow Dembski's scheme and, having arrived at the second "node," have somehow determined that the probability of the event in question is not "intermediate" but "small," in which case we proceed to the third "node" of the filter.
At the third "node" of the filter, according to Dembski's scheme, the choice is made between design and chance. Before analyzing the details of Dembski's procedure for discrimination between design and chance, let us briefly discuss a few general points.
One such point is the nature of design, and another is what can be called "the degree of design."
Regarding the nature of design, it seems reasonable to distinguish between various types of design. Even if we omit the host of vexing questions related to the possible design by artificial intelligence, we still can imagine at least three different kinds of design, namely a human design, an extraterrestrial's design, and a supernatural design. This question has been very thoroughly analyzed by Ratzsch [7]. (I am omitting the discussion of the design by either artificial intelligence or by natural processes because these types of design are completely absent in Dembski's theory.)
Dembski does not seem to acknowledge the differences between these three versions of design. On the contrary, he seems to stress the features common for all types of design. Remember Dembski's statement that design is a logical rather than causal category and that design does not necessarily entail a designer?
When we are dealing with a human design, usually we recognize design quite easily. Neither a "design theorist" such as Dembski nor the opponents of that "theory" will argue about the source of a poem or a novel, both readily attributing it to design and rejecting chance as a possible source of the text in question.
In case of a hypothetical extraterrestrial design, the situation is more complex. Since we have no experience with such type of design, we may be at loss when encountering certain objects which may look for us as having emerged through some chain of chance events whereas they may be products of a mind whose mental processes can be immensely different from ours. Dembski's filter seems to be hardly of help in such a situation.
If we turn to supernatural design, the problem is both similar and different as compared with extraterrestrial design. In the case of aliens we can at least reasonably assume that their designing activity is constrained by the same laws of physics we are familiar with. If we assume, as it is commonly done, that the supernatural designer is omnipotent, i.e. is not constrained by natural laws and is capable of creating new laws at will or breaking the existing laws in any particular case, then the distinction between law and design, as applied to a supernatural design, becomes meaningless, since the natural laws themselves are assumed to have been created by the supernatural designer. Again, Dembski's filter does not seem to be of help in that situation either.
Because of Dembski's generalization of the supposed indications of design, without accounting for differences between human, alien and supernatural design, his filter is useless for the most interesting discrimination between the three listed types of design.
In relation to Dembski's concept of specification, let us again take a look at Behe's example with Scrabble letters. In that example, whose versions have also been discussed by Dembski, two strings of letters are compared, one a meaningless combination and the other a phrase from Hamlet. According to the Dembski/Behe explanation, both strings have equally low probability of emergence by chance. We recognize design in the meaningful phrase because, according to Dembski's scheme, it is specified, i.e. conforms to a recognizable pattern, while the line of gibberish is not specified and therefore is attributed to chance.
I submit that the explanation by Dembski/Behe is not quite adequate. I believe it is more reasonable to conclude that if we see a string of Scrabble letters on a table, we attribute its occurrence to agency regardless of its being a quotation from Shakespeare or a piece of gibberish. Remember, that on page 11 of "The Design Inference" Dembski used the term agency as a synonym for design, although elsewhere he distinguishes between these two concepts.
(The readers familiar with Ratzsch's book [7] may notice that if design is used as a synonym for agency, this is different from Ratzsch's interpretation. The latter seems to interpret design as necessarily including a purpose on the part of the "designer." Since Dembski's approach entails separation of design inference from an inference to a designer, obviously the question of a designer's purpose becomes moot. Since this discussion is about Dembski's theory, I will assume that the only question we are really concerned with is whether an event occurred by chance or its causal antecedent can be traced to an intelligent agent, and that a purpose such an agent might or might not have, while may be of interest, will be a separate issue. Hence I will use the term "design" simply to mean that the event in question occurred because of an action by an intelligent agent, leaving out the question of purpose.)
Back to the example with the two strings of Scrabble letters, we do not think even for a minute that the letters in the gibberish sequence have lined up on the table by themselves, due to some chance process. Somebody had to make these letters, bring them to the room, place on the table and arrange along a straight line. We are confident all this was done by a human, i.e. the occurrence of that piece of gibberish was due to design (in the above defined sense) not any less than the occurrence of the phrase from Hamlet.
In one case the "designer" (or a group of "designers") made the letters, brought them to the room, placed them on a table, arranged them randomly along a straight line and stopped at that point of their "designing" actions. In the other case, a designer continued, taking care to arrange the letters in an order forming a meaningful phrase in English. It is possible to say that the meaningful string is more narrowly specified than the random string. The difference seems to be in the degree of specification but not in its presence in one string and absence in the other.
Review again the possible counter-argument that the difference between a meaningful text and a gibberish is in that the former entails a purpose, while the latter does not. We have to remember, though, that Dembski defines design simply as the only remaining option after law and chance have been eliminated. With such an interpretation, the question of purpose involved in design becomes moot.
Moreover, I believe that the common concept of purpose entails the concept of a conscious action. If an event resulted from a subconscious action it can hardly be attributed to a purpose even if the action was by an intelligent agent.
It is easy to imagine situations when a meaningful phrase resulted from a purposeless action, while a gibberish phrase has been created for a purpose. There are many examples of the former. Whoever has taken part in lengthy and boring meetings knows that very commonly the participants, while listening to the discussion, absentmindedly chew pencils, bend and unbend fingers, and often doodle and scribble on pieces of paper. The products of these subconscious actions are most often meaningless figures and nets of curves, but not too rarely they form some meaningful words and even phrases, created without consciously realizing that and which their creators would not be able to remember a minute after the meeting is over, not to mention explaining the purpose of those phrases.
Now turn to an example of a gibberish phrase created for a purpose. Look at the following line: "Epsel mopsel raisobes." This line is a quotation from a poem by a Russian poet A. Zakharenkov, printed in a collection "Strofy Veka" (Polifact Publishers, Moscow, 1997.) This sequence is gibberish, it has no meaning either in Russian or in any other language. Its author deliberately wrote this line as gibberish to create a certain comic effect. It was designed for a purpose.
Let us again review the question whether or not a string of letters must necessarily have an identifiable semantic meaning in order to be viewed as "specified."
Here is an example. Since 1912 many scholars all over the world have been investing a considerable effort trying to decipher the so-called Voynich manuscript (VMs.) A slightly magnified black-and-white photo of a segment of that manuscript is shown in fig.1.
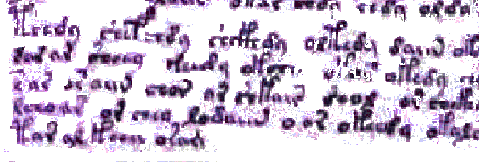
Neither the language nor the alphabet of that manuscript are known. All attempts to decode it have so far been unsuccessful. Therefore some scholars suggested that it has no meaningful contents but is a hoax, just over 200 pages of gibberish. I am of the opinion, based on a statistical analysis of the VMs's text and shared by the majority of those who have tried deciphering VMs, that it is a meaningful text. On the other hand, my colleague in the effort to apply the Letter Serial Correlation test to VMs, Dr. Brendan McKay, as well as some other scholars, is inclined to think that it is gibberish. However, regardless of the choice between the two mentioned views, nobody has ever doubted that VMs was written by some medieval author, i.e. that it is a product of design.
A glance at the text in fig. 1 makes it immediately obvious that we deal with an artifact, designed by a human mind, even though it is unknown whether or not the text is meaningful. Contrary to Dembski's scheme, the design is identified in this case without having available any "detachable" pattern, which, according to Dembski, is a necessary condition for recognizing design.
Does the above discussion mean that there is no difference between a quotation from Hamlet and a line of gibberish? Of course, there is a difference. It is in what can be termed as "degree of design." To place on a table a string of Scrabble letters arranged along a straight line requires design. Making a meaningful phrase requires, I would say, "more" of a design. Both the string of gibberish and the quotation from Hamlet are specified, but to a different degree. To form a quotation from Hamlet requires an agent who is more intelligent than it is sufficient to simply place a meaningless string of Scrabble letters on a table. Indeed, in the first case the intelligent agent must be familiar with Shakespeare's plays, while in the second case the letters could be placed on a table by an illiterate peasant. The recognition of different degrees of specification is absent in Dembski's discourse.
Let us note that Dembski's view of the difference between the two strings of Scrabble letters seems to indicate that he considers meaningfulness of the string as the indication of design, while the absence of meaning as an indication of chance. We will remember that when discussing Dembski's treatment of information.
An important point seems to be also that all of the above discussion is relevant only to human design. In the case of an alien design, and even more of a supernatural design, not to mention design by artificial intelligence, we may not know what the signs of design really are. In the case of a supernatural design, the requirements of meaningfulness may indeed be legitimate for recognizing design.
Let us now discuss specification from another angle.
According to Dembski, to qualify as specification, the event must be "detachable" and meet the condition of delimitation. In its turn, to be "detachable," the event must meet the conditions of epistemic independence of the side information and of tractability. While this multi-step scheme looks rather complicated, especially when Dembski renders it in a heavily symbolic mathematical form, when we review examples provided by Dembski himself or by his colleague Behe, we see that actually the idea underlying the discrimination procedure is not very complicated at all. In one example an astronomer recognized the configuration of a constellation in a pile of stones. In another example, we recognize a quotation from Hamlet in a string of Scrabble letters.
Actually all those convoluted notions of detachability, tractability and delimitation seem to be superfluous and the criterion of specification seems to boil down to the simple requirement that can be expressed as: an event is specified if it displays a recognizable pattern. Of course, if Dembski limited his discourse to such a brief and easily comprehensible assertion, he would not be able to write a whole book with its seemingly sophisticated mathematical apparatus.
What does recognizability entail? To recognize a pattern we must have in mind some image, independent of the pattern actually observed, to which we compare the observed pattern. That is actually the idea of "detachability," stripped of its sophisticated embellishments.
In view of the above, we can discuss Dembski's criterion of design without delving into the intricacies of his convoluted mathematical discourse.
g2. False positives
Dembski admits that intelligent agents can, in his words, "mimic" chance and that in such cases his filter produces "false negatives."
However, insists Dembski, his filter never produces "false positives." In other words, if at the third "node" of the filter the conclusion is that the event is due to design, this conclusion is reliable.
To support his assertion, Dembski suggests two lines of proof. The first proof of the filter's reliability, according to Dembski (page 107 in [3]) is a "straightforward inductive argument: in every instance where the explanatory filter attributes design and where the underlying causal history is known, it turns out design is present; therefore design actually is present whenever the explanatory filter attributes design."
While Dembski devotes several pages to the elaboration of this assertion, he does not substantiate it by providing any record which would indeed show his filter's impeccable reliability. How can he prove that, indeed, his filter correctly indicates design in every instance? At best, he may assert that in those few examples he has investigated, his scheme indeed correctly identified design, but how can he be sure that it is true for "every instance?" Indeed, he has reviewed in his publications only a few examples, thus hardly providing a basis for sweeping generalization (not to mention that we don't know whether or not his examples were deliberately selected to meet his requirements.)
Generally speaking, anecdotal evidence is not proof. However, when a categorical statement like that by Dembski is offered, anecdotal examples can legitimately serve as a rebuttal. In a few paragraphs, I will describe instances of "false positives," which, in my view, exemplify the lack of substantiation in Dembski's categorical assertion.
The second argument offered by Dembski to prove the immunity of his filter to false positives is (page 111 in [3]): "The explanatory filter is a reliable criterion for detecting design because it coincides with how we recognize intelligent causation generally."
In that statement Dembski seems to stand alone in knowing for sure how "we recognize the intelligent causation generally." I submit that such a statement is rather dubious. Dembski suggested his filter precisely as a better and more reliable tool for recognition of "intelligent causation." Now he justifies its alleged perfection by comparing it to how we do it without his filter. How exactly do we recognize intelligent causation? If we can do it without his filter, and we all know how we do it, what then is his filter for? If his filter, though, is indeed a hitherto unknown perfect tool for recognizing intelligent causation, which is superior to "how we do it generally," then how can the comparison to an inferior way "we do it generally" vouch for the filter's reliability?
Both arguments in favor of his filter's reliability only express Dembski's own personal view but hardly have evidentiary significance.
Let us see if indeed "false positive" are never produced by the explanatory filter.
I submit that Dembski's explanatory filter can and does produce false positives in many common situations. One example of a "false positive" produced by Dembski's filter was suggested by Ratzsch (the "tumbleweed case" in [3].)
Here is another example. This is a real story. I can easily imagine that many readers may disbelieve it and think that I have made it up. However unbelievable it may seem, it is true and I will tell it, trying to recall it as accurately as possible.
My late cousin Joseph (nicknamed Kot) was several years older than I. We always lived in different cities. He used to visit us from time to time, and the last such visit took place in 1939. When, in 1941, the German army invaded Russia, I lost all trace of him. In 1949 I lived in the city of Odessa, Ukraine. In April of 1949 I went to Moscow for a few days to give a talk in one of the research institutions. On my second day in Moscow, I went to the Okhotny Ryad street looking for a cafeteria to have lunch. It was close to noon, and the street was densely crowded by people moving in both directions. At some moment the crowd around me slightly receded for a few seconds and I saw a man walking toward me. To my amazement, I recognized Kot. I learned that he lived for the last couple of years in the city of Balkhash, several thousand miles from Moscow. Balkhash is a small town situated in the central area of Kazakhstan, on the shore of Lake Balkhash (which is unique in that it consists of two almost equal parts, one with sweet and the other with salty water.) My cousin wound up in that city due to some peculiar circumstances which are irrelevant to this story.
He was traveling with his wife and two daughters from Balkhash to his native city of Kharkov in the Ukraine for vacation. On the morning of that day, on his way from Balkhash to Kharkov, he arrived in Moscow, where he was to stay for only a few hours, and then depart for Kharkov in the afternoon. One of his daughters caught cold. He left his family at the railway station and took the subway to Okhotny Ryad to find a pharmacy.
It is obvious that the probability of a chance encounter with Kot in the described circumstances was minuscule.
It is easy to verify that the described event also met Dembski's conditions of detachability (which comprises conditional independence and tractability) and delimitation. Instead of delving into Dembski's detailed definitions of these concepts, let us simply recall his own example of an astronomer who recognized the configuration of a constellation in a pile of stones. The astronomer in that example recognized the pattern because he had the proper background knowledge he had in his mind the image of that constellation. This image did not affect the probability that the configuration of stones happened by chance (i.e. conditional independence.) He could easily create in his mind the image of the constellation in question (i.e. tractability.) The configuration actually observed was among those he had in his mind (i.e. delimitation.) Likewise, I recognized my cousin because I already had in my mind the image of him, which knowledge did not affect the probability of our chance encounter (i.e. conditional independence). I could easily create in my mind the image of Kot (i.e. tractability.) The image of Kot was among all those images I had in my mind (i.e. delimitation). If, according to Dembski, the astronomer's recognition of the configuration of a constellation was a specified event of low probability, then so too was my encounter with Kot.
In Dembski's view, recognizing the configuration of a constellation in a pile of stone leads inevitably to inferring design, i.e. to the conclusion that somebody intentionally arranged the stones in the observed configuration. Hence, if we accept Dembski's scheme, we have to conclude that my encounter with Kot was designed. It was not. This is a clear case of a false positive.
The story, however, had a continuation. In 1969 I lived in the city of Tver, some 120 miles north-west of Moscow. In April of 1969, exactly twenty years after my amazing encounter with my cousin, one morning I took a train to Moscow where I planned to stay for just a few hours and return to Tver the same evening. Close to noon I was walking on the same block of the same Okhotny Ryad street where twenty years earlier I had met Kot. Suddenly somebody hugged me from behind. I turned and, to my amazement, recognized my old friend Karl F. (Karl is alive and well and now lives in Brisbane, Australia.) Our friendship started in the fall of 1952 when we both worked at the same institute in Dushanbe, Tajikistan. It was based on our shared love for mountains. We climbed many mountains together in Pamir and Tien-Shan. The last time I met him before that encounter in April 1969 was in Siberia in 1959. Since then, I did not know his whereabouts. Now, in April of 1969, I learned from Karl that at that time he lived, of all places, in the city of Balkhash! He wound up in that forlorn city due to peculiar circumstances which are irrelevant to this story. He came to Moscow for only a few days.
I leave it to the readers to estimate the probability of our encounter at exactly that minute at exactly that particular spot, exactly twenty years after a similar encounter at the same location, with my cousin, a man whose name also began with the letter K, each time ten years after my previous meeting with each of them, both having come from the same remote town. The precise calculation of probability for the described events is difficult because many details of the situation have to be assumed without a verifiable information (for example, I can't confidently assert what exactly were the frequency and durations of Kot's and Karl's visits to Moscow, how many streets there are in Moscow, etc.) Therefore I will not provide specific numbers for that probability (although, making a few assumptions, I could roughly estimate it as being about ten to the power of minus fifty.)
Regarding a detachable pattern which is necessary, according to Dembski's theory, to infer design, if Dembski identifies such a pattern in the case of an archer hitting a target, certainly a much more pronounced specified pattern can be seen in the above story.
Let us now apply Dembski's design inference scheme to the described event. To this end, let us copy the design inference argument from Dembski's book in its symbolic form (page 49 in "The Design Inference") and add to it the description of the event in plain words. In the following scheme, Dembski's argument in its mathematically symbolic form, which was shown in one of the preceding sections of this article and designated as set (A) of formulas, is on the left, while my addition of the particulars of the event in question is on the right in the double square brackets.

Indeed? Isn't this a false positive at its extreme? Contrary to Dembski's confidence in the reliability of his scheme, which allegedly never produces false positives, such false positives can be expected in many situations.
If my extremely improbable encounters with Kot and Karl can be viewed as a rare exception, a rather more common example that immediately comes to mind is a raffle. Imagine a raffle in which ten million tickets have been sold, each bearing a seven-digit number, from, say, 0000001 to 9999999. Sweepstakes in which up to thirty million and even more tickets are distributed, for example by magazine peddlers, are quite common in the USA. The winning number is usually predetermined in advance, say that in our example it is 9765328. The probability of winning for each individual player is of course the same - one in ten million provided fraud is excluded. While this probability is not as exceedingly small as those sometimes calculated, for example, for the spontaneous emergence of a protein molecule, it is small enough to exclude law as a cause of winning. If John Doe won in an honestly conducted raffle, it was due to chance. However the event John Doe's winning - is clearly specified. Both the player and the winning number are specified. In particular, the winning number constitutes a recognizable pattern. The combination of small probability and recognizable pattern, according to Dembski's filter, determines design (in this case fraud) as the cause of that event. It seems to be a false positive.
Of course, Dembski might say that the probability in this case is not small enough to warrant the conclusion of design. Indeed, this is his argument when he discusses the case of Shoemaker-Levy comet (wherein he estimated the probability as being 10-8 - page 228 in "The Design Inference") insisting that his filter does not yield design easily. The probability of an event, according to Dembski, must be very low indeed to infer design. However, on page 189 of "The Design Inference," where Dembski discusses what constitutes a sufficiently small probability, he characterizes probability of 10-5which is 100 times larger than in our example, as sufficiently "small to eliminate chance in case the conditional independence and tractability conditions are also satisfied." The listed conditions are satisfied in our example. Anyway, the numbers in themselves are not crucial, it is the principle which is under discussion. Indeed, it can easily be shown that the absolute value of probability is of secondary significance, and one in ten million and sometimes much larger numbers, can in many instances be justifiably viewed as a sufficiently small probability for the purpose of design inference.
To this end, consider a small raffle in which only 100 tickets are sold, which, however, is played more than once. The probability of John Doe's winning once in that raffle, if it is conducted honestly, is, of course, 1/100. Assume now that John Doe won that raffle three times in a row. The probability of such a triple win is (1/100)3 which is one in a million. That is ten times larger than in the above mentioned sweepstakes where it was one in ten million. However, despite larger probability of the triple win in the latter case, we now suspect fraud, i.e. design, and justifiably so. In the latter case the probability of one in a million is obviously small enough to suspect fraud, while the smaller probability in the sweepstakes with ten million players is justifiably used for assuming chance. This shows that the meaning of a certain value of probability is not absolute but has to be viewed in relation to the specific circumstances of the event, which does not seem to be accounted for by Dembski's filter.
(A detailed discussion of the reasons for the different intuitive interpretation of the results in a large raffle played just once and small raffle played several times in a row, is given in Improbable Probabilities.
It should be stressed that the particular event to be analyzed is a specified player winning in the raffle/sweepstakes, not someone winning. If in the case of the large sweepstakes we decide that one in ten million is not small enough to warrant the design inference, then it should hold even more for the small raffle played three times, where the probability of the event in question is ten times larger. On the other hand, if we decide that the probability of one in a million is small enough to infer design in the case of a triple win, it should hold even more for the case of a large sweepstakes where the probability of the event is ten times smaller.
I believe the above examples show some of the deficiencies of Dembski's filter which can easily produce both false negatives and false positives. It can be expected that in many cases we will be unable to decide whether the probability of a specified event is small enough to infer design or is "intermediate" thus pointing to chance.
g3. Illusory patterns
I believe that there are whole classes of situations in which Dembski's explanatory filter is fully expected to produce false positives.
One such situation is that of an illusory pattern.
To clarify the concept of an illusory pattern, consider the following example. The Caucasus mountain range extends for several hundred miles. It comprises thousands of peaks, passes, dales and valleys, gorges and chasms, glaciers and moraines, etc. All these relief elements have different shapes, most of them quite irregular, although here and there parts of a mountain may form some more or less regular geometric patterns. The particular shape of this or that relief's element depends on an enormously large number of accidental factors so when we observe a particular mountain we realize that its particular shape has an extremely small probability. If we apply Dembski's filter to find whether or not that particular mountain's shape is due to chance or design, it would easily pass the first two nodes of the filter and lead right to the third, the crucial test in which we will look for a recognizable pattern. For the overwhelming majority of the mountains no pattern will be recognized, so the emergence of the particular shape of any particular mountain will be justifiably attributed to chance.
(Of course, some proponents of intelligent design can insist that everything is the result of design by a supernatural mind, so the irregular or sometimes seemingly regular shapes of the hills and gorges were designed that way. There is no rational way to reject such a statement. If, though, such a claim were made, it would make Dembski's filter absolutely unnecessary, since that filter allows for chance events to occur, while the above claim denies their existence altogether. Our discussion is within the framework of an approach which allows for chance and deals with the question of how to rationally distinguish between chance and design, in particular using Dembski's criterion.)
There is, though, in the Dombai region of the Caucasus range a mountain named Sulakhat. This word is a woman's name in the local language. Anybody looking up at Sulakhat from the valley circling that mountain immediately understands the reason for that name. From the valley the mountain looks like the perfect profile of a woman on her back, with the clearly delineated features of a young pretty face, neatly combed hair, taut breasts, arms crossed over her stomach, and slim legs slightly bent at the knees. The contours of the woman's body display all the features of a fine work by an accomplished sculptor. Many first-time visitors to Dombai refuse to believe that all they are seeing is an accidental combination of rocks and ice fields. Indeed, if we apply Dembski's filter, we clearly see a combination of improbability (complexity) with a recognizable pattern, which, according to Dembski, indicates design.
If, having climbed the mountain and having accurately measured the "body" of Sulakhat, we discovered that it is indeed a figure carved from a giant slab of stone, we could reasonably decide that the filter provided good reason to conclude that we saw the product of design.
Actually, this is a clear example of an illusory pattern. Indeed, as mountain climbers walk up the slopes of Sulakhat, they gradually discover that the sculpture-like shape is an illusion. The part that from the valley looks like a head turns out to be a combination of various rocks, scattered over a wide plateau and separated from each other sometimes by hundreds of feet. The two protrusions that from the valley look like a pair of breasts turn out to be of quite different shape and of grossly different size. They are located far apart and accidentally project toward the valley as though they are next to each other, thus falsely appearing of about the same size and of a similar breast-like shape. In other words, at a closer look, the alleged sculpture breaks down into an incoherent conglomerate of unrelated pieces. The explanatory filter has produced a false positive. The very low probability of Sulakhat's emergence by chance is indisputable. A recognized pattern is there for all (from the valley!) to see. "Design!" announces Dembski's filter. "Illusion," is the correct answer.
The described example of an illusory pattern can also be viewed as one more manifestation of the subjectivity of Dembski's criterion. From the subjective viewpoint of an observer who looks at Sulakhat from the valley, there seems to be a recognizable pattern. From the subjective viewpoint of an observer who has climbed the mountain, there is no recognizable pattern in the shape of that mountain. The criterion in question is subjective in regard to both false negatives and false positives.
g4. The nature and role of specification
In Dembski's scheme, specification is explicitly viewed as a category independent of probability. Moreover, he specifically maintains that the side information utilized to establish specification must be conditionally independent of the probability, expressing it as P(E|H&I)=P(E|H), where E stands for event, H is in this case the assumption that the event is due to chance and I is the side information.
In my view, the described approach is faulty. I submit that the procedure of design inference is essentially an estimation of the probability of either design or chance. Therefore the real role of specification is only in enhancing the probability of design as compared with the alternatives.
In Dembski's scheme, when we reach the third node of the filter, we first estimate the probability of the event in question assuming that it occurred by chance. If it turns out to be small, then, according to Dembski, we look for specification, i.e. for a recognizable pattern. If we find such pattern, it leads to the design inference.
Time and time again, throughout his books and papers, Dembski states that small probability in itself is insufficient to infer design. To infer design, according to Dembski, small probability must be accompanied by a recognizable pattern. In my view, Dembski's formula for inferring design unnecessarily introduces an artificial dichotomy between probability and specification. In fact, specification (i.e. a recognizable pattern) is not a factor independent of probability but rather only one of many factors affecting the estimate of the probability of design as compared with chance.
I guess that my approach is rooted in my background in statistical physics. The latter is a magnificent science, developed by such intellectual giants as Boltzmann, Maxwell, Gibbs, Clausius, Gauss, and other inordinately powerful minds. It has been established as a highly reliable penetration into reality. One of its salient features is that it clarifies the laws of thermodynamics, revealing the actual statistical nature of the latter. For example, statistical physics asserts that the predictions of the 2nd law of thermodynamics are not absolute but only determine the most probable outcomes of natural processes. The predictions of that law practically are highly reliable only because of their overwhelmingly larger probability as compared with any alternative occurrences. The extremely low probability of alternative events is the sole reason the laws of thermodynamics work so well despite not being statements of absolute truth.
While events may be affected by a multitude of factors, statistical physics incorporates all of them in one ultimate criterion the probability of the event in question.
Accounting for the great success of statistical physics, I see no reason why the same approach should not be utilized in discussing the probability of design vs. chance. There is no need to separate specification from probability as an independent factor. Following the proven approach of statistical physics, it seems more reasonable to view specification as just another factor contributing to the probability of design vs chance. Like in statistical physics, what really counts is the overall probability of either design or chance, regardless which components it comprises. One of these components may or may not be specification, i.e. a recognizable pattern. In some circumstances specification may be a more important contributor to probability than other factors, while in some other circumstances it may be a less important contributor. In certain situations specification may not be a contributor to the probability of design at all. In that, specification, i.e. a recognizable pattern, is not any different from many other factors contributing to the estimate of probability of design vs chance.
If we see a poem or a novel, we unequivocally recognize design because the probability of design is overwhelmingly larger that that of chance. In this particular case, specification, i.e. a detachable pattern, contributes to the large probability of design. However, it is by no means the only possible situation. We may encounter an item which does not look as any familiar image, and hence does not match any detachable pattern, but identify it as an obvious artifact, because many factors other than specification combine in an unequivocal indication of the overwhelming probability of design as compared with chance. The Voynich manuscript is just one example of such a situation.
Dembski's attribution of a special status to specification as compared with other factors does not seem to be justified by evidence.
The design inference is never absolute. It can only be made in probabilistic terms. If an event has a very small probability of occurring by chance, a hypothesis of design may be highly reasonable. Dembski asserts, however, that small probability is not in itself sufficient to infer design. If the event also displays a recognizable pattern, the probability of design becomes even larger. However, in principle it is still a hypothesis, albeit with a higher probability. If, as Dembski states time and time again, low probability in itself is not sufficient to unequivocally infer design, neither is the combination of low probability with specification, because all the latter does is simply decreasing the probability of chance. This in itself does not introduce a new quality into the inference procedure, but is only a quantitative step toward the hypothesis of design.
Indeed, as several examples discussed in preceding paragraphs have shown, sometimes design can be reliably inferred in the absence of a recognizable pattern, i.e. of specification (as in all cases of "false negatives" whose possibility Dembski admits) while in other cases specification does not ensure the reliability of the design inference (as in cases of "false positives" which have been shown to happen despite Dembski's assertion to the contrary.) Therefore the conclusion seems to be that the entire foundation of Dembski's scheme is built on sand.
Dembski is right when, unlike some of his colleagues in the "intelligent design movement," he asserts that low probability in itself is not sufficient to eliminate chance as the source of an event. Indeed, chance events of extremely small probability occur routinely every minute. However, this situation cannot be remedied by mechanically adding to the estimate of probability some other factor, be it specification in Dembski's sense or anything else. Whichever additional factor is taken into consideration, it may or may not change the estimate of the probability in question. Therefore the design inference is doomed to be probabilistic. This does not though prevent such an inference from sometimes being highly plausible, but this plausibility may be achieved both in cases when specification according to Dembski is present and in cases when no such specification is discovered. In the example of the Voynich manuscript, no Dembski-sense specification seems to be found, however the design inference is quite reasonable, although it is based solely on the overwhelmingly larger probability of design vs. chance.
Another comment in regard to Dembski's definition of specification can be made if we review his favorite example of archery. In that example, Dembski compares two situations. In one an archer hits a wide wall and afterwards paints a target around the arrow. This is, in Dembski's terms, fabrication. In the other situation, an archer hits a small target that was painted on the wall beforehand. This is specification, says Dembski.
Whereas the case of fabrication is simply not interesting, it is easy to see that the difference between the two situations is not that in the first case the event was not specified while in the second case it was. The event is obviously specified in both cases. The entire wall is just a larger target (i.e., constitutes a "recognizable pattern") than the small round target painted on that wall. The difference is in the size of the target, which, of course, is not a principal difference. The same difference exists between, say, a painted target which is 5 cm in diameter and a painted target which is 50 cm in diameter. In both cases the event is specified. The mere fact that in one case a target is painted while in the other case the entire wall is a target, does not distinguish the events in terms of specification. The difference is only in a different probability of a hit.
Later we will discuss Dembski's theory of complexity in which he ties together three concepts: complexity, probability and difficulty of solving a problem. According to that theory, the more difficult is it to achieve a certain result, the smaller is its probability (which seems to be a trivial observation; but let us wait until we discuss this theory in detail.) When discussing the archery example, Dembski seems to forget his own definitions of the triad of probability, complexity, and difficulty.
In the case of the entire wall serving as a target, the probability of hitting it by chance is much larger than in the case of a small painted target. The same can be said about two targets, one 5 cm in diameter and the other 50 cm in diameter. This example illustrates the artificial character of Dembski's separation of specification from probability.
Specification in itself plays no independent role in the discrimination between design and chance, but is just a constituent of probability.
Likewise, if we see a meaningful text, we conclude that its emergence by chance was highly unlikely. The fact that the text meets a recognizable pattern points to design not because it adds some independent argument in favor of design, but because it enhances the probability of design. Every factor works either for or against probability, and specification is just one more contributor to the estimation of probability rather than a factor independent of probability. It is not combined with low probability, as Dembski maintains, but is incorporated into probability as a part of the necessary background information.
Let us discuss once again Dembski's example with archery competition. If there is a target painted on a wall and the archer hits that target, this is, according to Dembski, a specified event of small probability which therefore must be attributed to design. This conclusion, according to Dembski, is made because the event (hitting the target) meets the conditions of detachability and delimitation. Detachability, it turn, incorporates conditional independence of the background knowledge and tractability. In relation to the archer's success, let us discuss the conditional independence of the background knowledge which, according to Dembski, is necessary for design inference. From Dembski's explanations and examples seems to follow that the background knowledge relevant to the problem at hand boils down to the recognizability of the target. The painted target is specified, i.e. recognizable. The recognizability of the target does not affect the probability of the hit (i.e. conditional independence is satisfied) therefore when the arrow hits the target, we conclude the event in question was due to design. Any side information which may affect the probability of the hit, is, according to Dembski's scheme, irrelevant for design inference. For the sake of discussion, let us accept Dembski's scheme which asserts that the successful hit must be unequivocally attributed to design. (In other words, ignore the contribution of laws of mechanics and such chance events as an accidental gust of wind or a small earthquake at the moment of the archer's action, and the like).
Imagine, though, that prior to the archers' competition, we watched the archers exercising for several days. Imagine that archer A is a world champion with a record of hitting the target 98% of the time, while archer B is a beginner who tried many times to hit the target as we watched him and failed to do so in all of his attempts. Thus we acquire knowledge about the two archers in question, which obviously affects our estimate of the probability of success for both archers at the competition. According to Dembski's scheme, this knowledge does not meet the condition of detachability because it is not conditionally independent. Hence, according to Dembski's scheme, the knowledge about the skills of the two archers in question has no bearing on design inference. Imagine, though, that on the day of the actual competition both A and B successfully hit the target. According to Dembski' scheme, design inference is equally justified in both cases. I think, though, that our conclusion will be different in the two cases. In the case of archer A with his record of 98% success, we will confidently attribute his success to his skill (i.e. to design). In the case of archer B we will justifiably attribute his success to his luck (i.e. to chance). In this example, the choice between chance and design is made based on the background information which, contrary to Dembski's scheme, is not conditionally independent.
Furthermore, in the case of archer A, despite the high probability (98%) of a perfect hit, when the archer in question indeed hits the target, we do not conclude it is due to law, as, according to Dembski, is to be done in the case of high probability (as Dembski's scheme prescribes for the first node of his filter). We conclude that it was due to design, and applaud the archer's skill, while in Dembski's scheme the design inference (see the third node of the explanatory filter) necessarily requires a very low probability of the event in question. (As was discussed earlier, the archer's success has to be attributed to a combination of design and law; Dembski's scheme, though, does not recognize such a double attribution, hence we do not need to account for it when discussing that example within the framework of Dembski's theory.)
One more comment about Dembski's analysis of specification/pattern seems to be in order. Recall again his example of an archer. If the archer hits the target, we identify, according to Dembski, specification. However, describing this situation, Dembski in some instances mentions just a single hit as being sufficient to qualify as specification (in particular such an interpretation follows from the definition of pattern, page 136 in "The Design Inference") while in some other instances (for example, on page 13) he mentions an archer hitting the target a hundred times in a row, and that repeated success is viewed as an indication of design (i.e. of the archer's skill.) He does not seem to see the difference between these two situations.
Indeed, besides the examples of archery, the definition of a pattern given by Dembski (page 136 in "The Design Inference") seems to make clear that in his scheme the repetition of an event is not considered a factor in determining a pattern.
I believe a repetition of an event is a very important factor in a design inference, and Dembski seems to have missed it. To see why the repetition is important, imagine two situations. In one case, an archer shoots from a certain distance of L meters and hits the target just once. In another case the archer shoots from a much shorter distance N<L but hits the target 10 times in a row. If we adopt Dembski's theory of probability complexity difficulty (which we will discuss later) we can assign a certain value of probability to the success in both cases. Since N is shorter than L, it is easier to hit the target from N meters. Assume that the difference between L and N is such that the probability of hitting the target 10 times in a row from N meters is exactly the same as hitting it just once from L meters. Despite the equal probabilities in these two situations, I believe our intuitive judgment will be different in the two cases. In the case of just one hit we will be uncertain whether to attribute the archer's success to his skill (i.e. to design) or to chance. Indeed, however small the probability of hitting the target by chance may seem to be, it is not zero. If the archer hit the target just once, it might well be attributed to luck, i.e. to chance. In the second case, we rather confidently attribute the archer's success repeated ten times in a row to his skill (i.e. to design) despite the probability of chance being in that case not less than in the previous case.
We have to acknowledge the substantial role of a repetition of an event in the procedure of attributing it to either chance or design. Dembski's definition of a pattern and hence of specification fails to recognize that factor.
From yet another angle, there are various classes of events regarding the discrimination between chance and design. On the basis of the same type of background information, some events are readily recognized as having been designed, while some can resist such discrimination. If we find a book of poems, we easily recognize it as a result of design. This discrimination is made on the basis of our background knowledge. In particular, our experience tells us that humans write poems and print books and we have seen many of them and know that they are the products of human design. The same relates to Paley's watch and a myriad of other objects which are familiar to us as a part of our ken. However, there are other classes of objects, and one example of such is any biological structure. A DNA molecule has a very complex structure and carries a lot of information (in the sense of information theory). However, our ken does not include any knowledge which would make us conclude that it is the product of deliberate design. The pattern seemingly present in a DNA strand, is not "detachable" using Dembski's term, as that pattern is not recognizable.
This would not matter if we had knowledge of some other factors which, if combined, would point to an overwhelming probability of design vs chance. Unfortunately, we have no such knowledge. Biological structures display enormous complexity, but this in itself does not indicate design because structures of unlimited complexity can emerge in any stochastic process. (More about this in the section on information.) We do not possess any relevant background knowledge which would enable us to discern design in biological structures.
I take the liberty of giving a peculiar example. The famous Russian anthropologist of the 19th century Nikolai Miklukho Maklai spent a long time among the aborigines of New Guinea studying the ways of life, the language, the habits and mores of those tribes. When the ship that brought Maklai to the island appeared in view, the aborigines who had never before seen such a big ship, decided that it came from heaven and that the crew members were gods. As a precaution, Maklai never tried to disabuse the villagers of their belief. Moreover, to reinforce their belief, he sometimes would remove his artificial teeth, to the villagers' amazement. Their ken did not include the knowledge of artificial teeth, so they viewed Maklai's action as a miracle effected by supernatural forces. Obviously, such an explanation was unjustified and similar to the interpretation of the DNA structure as the result of supernatural design.
It can be added that emergence of biological structures could occur without an intelligent designer, but still in a non-random way. Indeed, the Darwinian explanation of the origin of biological structures actually emphasizes the non-random factors in the evolution (see, for example, the popular book "The Blind Watchmaker" by the prominent biologist Richard Dawkins, W.W. Norton & Company, 1996). There are theories offering plausible mechanisms for such occurrences one such mechanism is described, for example, at Jigsaw model of the origin of life).
My conclusion is that Dembski's discourse regarding his highly acclaimed explanatory filter shows that his filter is often not a reliable tool to identify design. It often seems to fail even in cases of human design. This seems to be especially true in regard to supposed supernatural design, which seems to be the most interesting case.
In "The Design Inference," Dembski devotes the whole of chapter 3 (pages 67-91) to the discussion of probability and likelihood, and offers many notions related to probability in other chapters throughout his books, as well as in his papers.
Probability and likelihood are by no means novel concepts. Both have been discussed many times before Dembski. (A discussion of the conventional concept of probability, which is designed for non-experts, is given at Improbable Probabilities).
In probability theory there are various definitions of probability, such as the classical definition, frequentist definition, geometric definition, statistical definition, and finally the axiomatic definition given by Kolmogorov. There is also the so-called Bayesian approach in which distinction is made between three versions of probability, referred to as prior probability, posterior probability, and likelihood.
On pages 78-79 of "The Design Inference" Dembski briefly discusses the frequentist and classical definitions, and on pages 67-69, the Bayesian approach. (With his rather typical lack of excessive modesty, Dembski claims on page 86 "a huge advantage" of his approach as compared to the Bayesian). He points to certain limitations of each of those approaches. However, he does not mention any other definitions of probability, including that by Kolmogorov. Kolmogorov's axiomatic definition of probability is the most rigorous and the most general, and, on the one hand, encompasses all other definitions as particular cases, and, on the other hand, overcomes the limitations of all other definitions.
Having discussed the limitations of the classical and frequentist definitions as well as of the Bayesian approach, Dembski offers his own definitions of probability and likelihood. Here is Dembski's definition of probability (page 70 in "The Design Inference"):
Definition. The probability of an event E with respect to background information H, denoted P(E|H) and called "the probability of E given H," is the best available estimate of how likely E is to occur under the assumption that H obtains.
On page 78 of "The Design Inference" we find the following definition of likelihood:
Definition.
The likelihood of an event E
with respect to the background information H, denoted ![]() (E|H) and called
"the likelihood of E given H," is that number, or range of numbers in the
unit interval [0,1] denoting how likely E is to occur under the assumption that
H obtains and upon the condition that H is as effectively utilized as possible.
(E|H) and called
"the likelihood of E given H," is that number, or range of numbers in the
unit interval [0,1] denoting how likely E is to occur under the assumption that
H obtains and upon the condition that H is as effectively utilized as possible.
If Dembski offers his own definitions of these concepts, one may expect that such new definitions will shed new light on the matter, or at least reveal some new facets in those concepts, or maybe provide a more convenient or a shorter way to handle these concepts. In my view, they do none of the above.
Let us first look at the definition of probability. I submit that it is not a real definition and makes little sense.
On the one hand, this "definition" correctly lists two essential characteristics of probability. Indeed, probability is nothing more than an estimate of how likely is an event to occur, this estimate's cognitive value being only as good as the available information about the situation at hand. If that information changes, the estimate of probability changes as well. The more information about the situation is available, the better is the estimate of probability. However, while the characterization of probability as an estimate which is dependent on the available information is correct, it does not tell us anything new because it has been discussed many times before Dembski. Since his "definition" contains practically nothing beyond the quoted statement, the entire "definition" does not offer anything new.
On the other hand, Dembski's definition lacks a crucial element. This element may be expressed by the word "quantity." Probability is a quantity and makes sense only if it is assigned a numerical value. All existing definitions of probability, whatever their limitations, and whatever differences between them, include prescriptions of how exactly to assign to probability that numerical value. Dembski's "definition" provides no indication whatsoever that the "estimate" in question must actually be assigned a numerical value and even less of how to determine the latter. Therefore his definition of probability is not only inferior to those definition suggested hitherto, but is not really a proper mathematical definition.
The reference to "the best available estimate" by no means saves his "definition." How do we translate "the best available estimate," even if such has been reliably made, into a numerical value? Moreover, what are the criteria enabling one to distinguish "the best available estimate" from, say "the second best estimate," or from a poor estimate?
Dembski tries to clarify his idea by indicating that the determination of "the best available estimate" is to be made by "the community of discourse." While this assertion may have a nice sound, it is actually of little substance. What are the criteria enabling one to determine what the agreement within "the community of discourse" is?
On page 88 we read: "Within a community of discourse at a particular time probability is therefore uniquely determined."
Indeed? I wish this were true. Recall, for example, the ongoing dispute about the probability of appearance of a so-called "code" in the text of the Bible. (See, for example B-Codes Page). The dispute about this matter within the relevant "community of discourse," which included prominent mathematicians, reminded, in the words of one of its participants, Professor Barry Simon, of a street fight. Proponents and opponents of the "code" have offered vastly differing estimates of the probability in question, each side offering a host of arguments. While only one side of the dispute was correct, the dispute has not brought about a consensus.
Other examples of disputes among scientists in regard to the calculation of probabilities are given at Improbable Probabilities. No, Dr. Dembski, quite commonly there is no such thing as an agreement within the appropriate "community of discourse" regarding the probability of various events.
The vagueness of the concept of an estimate agreed upon by the "community of discourse," which may be handy in some philosophical treatise, seems to make it rather out of place in a supposedly rigorous mathematical discourse.
Let us now look at Dembski's definition of likelihood.
The concept of likelihood is commonly used in the Bayesian probabilistic approach, where it is rather simply and rigorously defined. This concept has also been used in information theory, the field in which Dembski, according to his admirers, is an expert.
Whereas an estimation of probability which is made assuming certain background information (a hypothesis) mathematically formalizes the logical procedure of deduction, the Bayesian approach mathematically formalizes the logical procedure of abduction (a brief discussion of that procedure can be seen at The Anthropic Principles Reasonable and Unreasonable).
On pages 67-69 of "The Design Inference" Dembski discusses Bayes's theorem and its constituent concepts, prior probability,posterior probability, and likelihood. Then Dembski offers his own definition of likelihood quoted above. Unlike the case of his definition of probability, this time his definition includes a reference to a numerical value ("a number or a range of numbers") which is to be assigned to likelihood. However, like in the case of probability, the "definition" of likelihood provides no indication of how precisely the numerical value in question has to be chosen, and therefore it also is not a proper mathematical definition.
If we compare the two Dembski's definitions - that of probability and that of likelihood, it is hard to see any distinction between them. Both definitions contain as their core the identical phrase "how likely E is to occur." Hence, essentially both try to define the same concept expressed by that phrase. One may point to two differences between the two definitions. One is that probability is estimated "under the assumption that H obtains," while likelihood is estimated "under the assumption that H obtains and upon the condition that H is as effectively utilized as possible." The other difference is that probability is determined as "the best available estimate," while the definition of likelihood requires us to assign to that concept a number (or numbers) within a certain range (although it does not provide any prescription of how such number is to be chosen.) Otherwise both definitions are identical, word for word.
It is easy to see, however, that the two mentioned differences are essentially inconsequential. Likelihood is defined with reference to H being "as effectively utilized as possible," while probability is defined without referring to that requirement. On the other hand, probability is defined with reference to "the best available estimate." Note that H stands for "background information," i.e. it does not refer to the conditions determining the actual occurrence of the event in question. It is hard to imagine that "the best available estimate" could be made without utilizing all relevant available information H "as effectively as possible." If the estimate were not to account for all available information H "as effectively as possible," obviously the estimate would not qualify for being "the best available." (The definition of likelihood, if considered in itself, may create an impression that the requirement of H being utilized as effectively as possible is a part of the conditions leading to the occurrence of E. However, Dembski's detailed elaboration which follows his definition (pages 80-81) makes it clear that he actually meant that H is the information which must be effectively utilized for the estimate of likelihood.) Hence, both definitions seem identical in that respect, while phrased slightly differently. Then the only difference between probability and likelihood, according to Dembski's definitions, interpreted literally, seems to be that likelihood is to be assigned a number, while probability is simply some non-numerical "estimate."
However, on pages 87- 88 we read the following explanation regarding "the best available estimate" : "'Estimate' signifies that an event is being assigned a number between 0 and 1 (or a range of numbers, or no number at all) which, in light of relevant background information, reflects how likely it is for an event to occur."
Hence, probability has to be assigned a number after all (which, of course, is indeed necessary.) Why, then, is assigning a number mentioned only in the "definition" of likelihood but not in the "definition" of probability? If the latter has to be assigned a number between 0 and 1, exactly as prescribed for likelihood by Dembski's "definition," what is the difference between his "definitions" of probability and likelihood? Dembski's two supposedly different "definitions" actually purport to define exactly the same concept.
Since Dembski's definition of likelihood (as well as of probability) offers no indication of how to actually determine the value (or a range of values) which is a necessary parts of the definition, this definition is actually reduced to a pure tautology. It states an obvious platitude - the more likely is the event's occurrence, the larger is its likelihood, or equivalently, the more probable is the event's occurrence, the larger is its probability.
I believe we would be better off sticking to the concepts of probability and likelihood which have been in use in probability theory for quite a while and which seem to work reasonably well.
Dembski's eagerness to offer his own supposedly innovative concepts of probability and likelihood can be humanly understood but these concepts in his interpretation do not offer anything new, lack crucial elements necessary for mathematical definitions, seem to have no useful purpose and at best only introduce notations.
Dembski's colleagues sometimes refer to him as a "design theorist," sometimes as an "information theorist," and sometimes as a "probability theorist." I admit that I am not a probability theorist. I am a physicist. I have, though, many times taught a university course on statistical physics, both for undergraduate and graduate students. Statistical physics is based on probability theory, and necessarily includes an introductory chapter, where probability theory is discussed. Based on my background in probability theory, I formed the opinion that Dembski's definitions of probability and likelihood are not really useful. However, allowing for the possibility that I did not grasp some hidden meaning in Dembski's discourse, I decided to get a second opinion.
I emailed Dembski's definitions of probability and likelihood to a prominent mathematician. This person is an expert in probability and statistics, the author or co-author of numerous publications in these fields, printed in the most prestigious scientific journals and collections, as well as an editor of a pertinent journal, and a member of the Academy of Sciences in his country. This scientist has not read any books or papers by Dembski, nor is he involved in the dispute about intelligent design. In my message to that scientist I did not mention intelligent design, but simply copied verbatim Dembski's definitions of probability and likelihood and asked that scientist to evaluate those definitions. Here is the quotation from that person's reply: "It doesn't work for me, as these definitions sound like mumbo-jumbo."
This reaction from a prominent professional mathematician is easy to understand if we recall that Dembski's definitions of probability and likelihood do not provide any basis for a quantitative estimate of the quantities to be defined, are ambiguous in many respects and contain some constituent concepts each requiring its own prior definition.
Therefore Dembski's entire chapter devoted to probability seems to be a useless exercise whose removal from his book would hardly cause any harm to the latter.
The essence of Dembski's complexity theory can be succinctly expressed by the following two quotations. On page 92 of "The Design Inference" we read: "Whereas probability theory measures the likelihood of an event, complexity theory measures the difficulty of a problem." On page 114 of the same book we read: "Probability measures are disguised complexity measures." The "disguise," according to Dembski, is in that probability and complexity differ only in direction and scale (page 115).
If
the last statement is true, why is there a need for a complexity theory besides
probability theory? Small
probability means, according to Dembski, large complexity, and vice
versa. The range in one case is
[0,1] and in the other ![]() Otherwise, probability values can be mapped into complexity values and vice
versa.
Otherwise, probability values can be mapped into complexity values and vice
versa.
The definition of complexity, according to Dembski (page 94 in "The Design Inference") is:
Definition.
The complexity of a problem Q
with respect to resources R, denoted by ![]() (Q|R) and called "the complexity
of Q given R," is the best available estimate of how difficult it is to solve
Q under the assumption that R obtains."
(Q|R) and called "the complexity
of Q given R," is the best available estimate of how difficult it is to solve
Q under the assumption that R obtains."
As Dembski indicates, "this definition closely parallels the definition of probability given" in another section of his book.
I believe the above assertion requires an amendment. With all the inadequacy of Dembski's "definition" of probability, discussed in the previous section, it was at least correct in some limited abstract way, qualitatively defining certain real features of probability. On the other hand, his definition of complexity is rather arbitrary as it seems to unduly generalize a particular class of situations, while being completely off the mark for many other possible situations (I will discuss this in the next section.)
Dembski also offers a definition of a quantity which is supposed to stand in the same relation to complexity as likelihood (in Dembski's interpretation) stands in relation to probability. On page 99 of the same book, we read:
Definition.
The difficulty of a problem Q
with respect to resources R, denoted by ![]() (Q|R) and called 'the difficulty
of Q given R,' is that number, or a range of numbers, in the interval
(Q|R) and called 'the difficulty
of Q given R,' is that number, or a range of numbers, in the interval ![]() is to solve under the assumption that R obtains and
upon the condition that R is as effectively utilized as possible."
is to solve under the assumption that R obtains and
upon the condition that R is as effectively utilized as possible."
Both definitions that of complexity and that of difficulty - define
the object of definition in the same words: "how difficult it is to solve Q"
in the first definition and "how difficult Q is to solve," in the second,
which is, of course, exactly the same. One
seeming difference between the two definitions is in that the first one requires
"the best available estimate," whereas the second requires assigning a
number (or a range of numbers) to the quantity to be defined. However, if we
look further at Dembski's discourse, we find that, while using the expression
"the best available estimate" in regard to complexity, he actually means a
number as well as in the case of difficulty. Indeed, on page 110 of "The
Design Inference" we read: "What do the numerical values of complexity
signify? So far all I have said about complexities is that they range between 0
and ![]() with 0 signifying minimal difficulty (typically no difficulty at all),
with 0 signifying minimal difficulty (typically no difficulty at all), ![]() signifying maximal difficulty..." Recall
that, contrary to the quoted sentence, in his definitions Dembski assigned a number (or a range of numbers) in the interval
signifying maximal difficulty..." Recall
that, contrary to the quoted sentence, in his definitions Dembski assigned a number (or a range of numbers) in the interval ![]() only to "difficulty," but not to "complexity." From the last quotation it follows, though, that indeed, in full
agreement with my interpretation, Dembski himself erases any difference between
complexity and difficulty. The difference in wording in the two definitions does
not actually represent any real difference between the two concepts to be
defined.
only to "difficulty," but not to "complexity." From the last quotation it follows, though, that indeed, in full
agreement with my interpretation, Dembski himself erases any difference between
complexity and difficulty. The difference in wording in the two definitions does
not actually represent any real difference between the two concepts to be
defined.
The second apparent difference between complexity and difficulty is in that the definition of complexity only requires the resources R to obtain, while the definition of difficulty requires additionally that the resources are as effectively utilized as possible. However, the definition of complexity requires "the best available estimate." Obviously, if resources R are not assumed to be utilized "as effectively as possible," the estimate based on such an incomplete assumption is not "the best available." The requirement of the estimate being "the best available" necessarily means the assumption of resources being utilized "as effectively as possible."
Furthermore, like Dembski's definition of probability and likelihood, those of complexity and difficulty provide no indication of how the numerical values are to be assigned to either of the two quantities in question. Instead, Dembski again offers the vague concept of "the best available estimate," which, in turn, is predicated on the concept of "community of discourse." The latter is a nebulous notion and as such hardly has a legitimate place in a supposedly rigorous mathematical definition.
Since Dembski's definition of difficulty provides no information of how to actually determine the number (or range of numbers) which are necessary parts of the definition, the latter does little more than assert that whatever has a larger difficulty is more difficult. Moreover, from these definitions it also follows that, because in Dembski's theory 'complexity' is defined exactly like 'difficulty,' whatever is more complex has a larger complexity. True! It is as true as assertions that whatever has a larger size is larger, and whatever is more bitter has a larger bitterness, and as any other tautology.
The conclusion: Dembski's supposed definitions of complexity and difficulty do not meet requirements for real mathematical definitions and at best only introduce notations. They do not seem to serve any useful purpose.
As was mentioned in the preceding sections, probability theory, with all of its variations and competing concepts, seems to be much better substantiated than Dembski's quasi-rigorous exercise. There is an analogous situation in the case of complexity as well. Although complexity theory is not yet developed to the same extent as probability theory, it has to its credit a number of substantial achievements. In particular, a serious theory of complexity was developed in the sixties under the name of Algorithmic Theory of Probability/Randomness (ATP) Dembski discusses the theory in question (for example, see pages 167-169 in "The Design Inference") but seems to ignore it when approaching complexity from his own standpoint.
The theory in question defines complexity in connection with the concept of randomness. While this theory is often discussed in terms of strings of binary digits, it is actually quite universal and applicable to a wide variety of situations. In that theory complexity is assigned a quantitative measure. Complexity increases along with the increase of the degree of randomness of a system. The more random is the system, the more complex and, therefore, longer in a binary representation becomes the algorithm which describes the system. The fully random system cannot be described by any algorithm (or program) which is shorter than the system itself. In other words, a fully random system and the algorithm which describes it are identical. The less random a system is, i.e. the more its structure is determined by a rule, the shorter the algorithm (or program) describing that system can be. Consequently, ATP defines complexity of a system as the minimal size of an algorithm (or program) which can "describe" the system.
While there are certain facets of ATP which have not yet been fully explained, it is a powerful and largely consistent theory. As can be seen, unlike Dembski's exercise in complexity, ATP does not relate that concept to the difficulty of solving a problem.
Regardless of his "definitions," Dembski's assertion that complexity is equivalent to the difficulty of solving a problem, and that, in its turn, translates into a small probability of the event, seems rather dubious. At best, such a notion may be true for only a narrow class of events.
An example of an event whose complexity indeed parallels the difficulty of solving a problem, which is given in Dembski's writings more than once (but actually was already discussed before Dembski by Dawkins in "The Blind Watchmaker") is that related to a safe combination lock. Such locks have a very large number of possible combinations of digits, of which only one constitutes the code that opens the lock. If the opening combination comprises, say, five two-digit numbers, the opening code can be viewed as quite complex. This complexity translates into a large difficulty of correctly guessing the combination and hence into a very small probability that an attempt to open the lock by randomly choosing some combination of five two-digit numbers will succeed.
However, there are many classes of events for which Dembski's scheme is not only inadequate, but in which the relation between complexity, difficulty, and probability is opposite to that assumed by Dembski. Let us review a few examples.
First, there are situations in which we are not interested at all in solving any problem but may be quite interested in estimating the complexity of a system. In such situations Dembski's definition of complexity which equalizes it with difficulty of solving a problem is irrelevant. Such situations are common in psychology, geography, economics, crystallography, and in many other areas of knowledge.
Assume that we wish to compare the structures of two objects which we have no intention or need of ever building. In such cases we are not interested in either the available resources for building these structures or in the difficulty in Dembski's sense. The complexity of those structures may be very much of concern, but in this case Dembski's definition is not at all helpful.
Here is a specific example of a situation in which the relation between complexity of a system and difficulty of a problem is opposite to Dembski' scheme.
In research aimed at the development of certain types of photovoltaic devices, a need had arisen to deposit electrochemically a thin layer of metallic molybdenum on various substrates. A layer of molybdenum, if successfully deposited, usually contains no more than two different phases. However, because of electrochemical constraints, mainly connected with the low overpotential of hydrogen on a molybdenum surface, the electrochemical deposition of pure molybdenum turned out to be very difficult to achieve. The problem is removed, however, if instead of pure molybdenum, an alloy is deposited containing over 98 percent molybdenum, the rest being metallic nickel and also a small percentage of hydrogen. Such an alloy can be deposited under a rather wide range of conditions and its properties are reasonably close to those of pure molybdenum, thus solving the problem at hand. However, the alloy in question has a much more complex structure than a pure molybdenum layer has. It contains a conglomerate of various phases, such as NiMo, at least three phases of Ni, hydrides of both Ni and Mo, etc. In this case, the difficulty of solving the problem at hand in no way matched the complexity of the system.
Another example is from my experience as a mountain climber. This is a very clear example of complexity not at all being tantamount to difficulty as assumed by Dembski. For example, a steep slope covered by smooth ice has a much simpler relief than a rocky slope of a very complex shape. However, the difficulty of climbing over the smooth and steep ice may substantially exceed the difficulty of climbing over a rocky slope where it may be actually quite easy if the rocks, as is often the case, provide multiple cracks and ledges immensely facilitating the climber's ascent. Also, it is much harder to scale the steep and smooth face of rock whose relief is quite simple than a rock whose face has a complex relief with multiple irregularities. In that example, the complexity of the path to the summit is much larger for a path which is much easier to negotiate and thus to solve the problem at hand.
One more example can be taken from the computer science. The concept of complexity in that field of science refers to the efficiency of a program, i.e. to the number of computational steps the program needs to perform a certain task (i.e. to solve the problem at hand), given a certain amount of data. The most efficient program (or algorithm) is such that requires the minimal number of the steps. Such an algorithm is defined in computer science as having the minimal complexity. However, there is no parallelism between the complexity in the above sense and the complexity of the algorithm's structure. Often the computational algorithm that is the most efficient, i.e. has the minimal complexity in the sense of computer science, is much more complex in its structure than the less efficient algorithms.
The situation in the above examples, while contradicting Dembski's scheme, is fully compatible with the concept of complexity in ATP.
If we turn now to Dembski's thesis that probability is just disguised complexity, it is easy to provide a multitude of examples to the contrary. I submit that a more common situation is one in which simplicity translates into a larger difficulty and therefore a smaller probability, which is contrary to Dembski's theory.
In Irreducible Contradiction, an example of pebbles found on a beach was discussed. I compared two samples, one a pebble of irregular shape and the other a perfectly spherical piece. Whereas the perfectly spherical piece can be described by a very simple program, a pebble of irregular shape requires for its description a much more complex program. However, contrary to Dembski's scheme, the spherical piece must be reasonably attributed to design, while the pebble of irregular shape, to chance. Many similar examples can be suggested.
According to Dembski's scheme, complexity is tantamount to low probability, and, hence, points to design, whereas simplicity, which is the lack of complexity, must point to chance. The simple example with two stones shows that more often than not, the actual situation is opposite to Dembski's scheme: simplicity is often a sign of design, while complexity often points to chance.
Before discussing the particular features of Dembski's treatment of information, let us make some preliminary comments of a general character.
There exists a well-developed science named "information theory." It started with the publications (in 1948) of a paper by Claude Shannon. A seminal concept of the theory in question is "information," which turned out to be very viable and has since become an almost a household term.
In a certain sense, the name "information theory" seems to be due more to tradition than to its essence. Perhaps a more appropriate name for it would be "communication theory." (Indeed, Shannon's classic paper of 1948 was titled "A Mathematical Theory of Communication".)
In fact, what information theory studies is the communication process, viewed as the transmission of information, regardless of the presence or absence of a meaningful message in that information. This choice of the definition of information was justified for at least two reasons. First, the process of information's transmission is not affected by that information's semantic content. Second, the originators of the information theory did not possess a method for measuring the semantic content. Therefore, for the purposes of communication theory, which is the essence of information theory, the definition of information in that theory was not only completely adequate but also very logical and convenient. However, it becomes inadequate if we wish to use the term information in connection with its semantic content.
Information is neither a substance nor a property of some substance. Essentially, information is a measure of a system's randomness, as we will discuss in more detail later. Therefore, the assertions that information can exist in some abstract way independent of a material medium, or that it is conserved (like energy in physics) seem to be dubious propositions. Information can be unearthed, identified, sent, transmitted, or received, and generally handled in whichever way, only if it is recorded in the structure of a material medium (the latter including electromagnetic waves.) For example, this record can be a combination of microscopic magnetic vectors in the layer of some metal oxides deposited on the surface of a disk. These magnetization vectors, each representing the magnetization of a tiny element of the oxide layer, can be oriented in either of two directions, one direction corresponding to a recorded 0, and the opposite direction, to a recorded 1. For all intents and purposes, the described string of "zeros" and "ones" represented by alternating directions of magnetization vectors is a "text."
There are many other ways to record information, but it always requires a material medium, in which a certain structure is created by the process of information's recording. Such text can be transmitted from one medium (source) through a communication channel to another medium (receiver.) Since the methods of information's recording, i.e. the physical, chemical or biological processes utilized for information's recording may be different in the source and in the receiver, and both are usually different from the process in the medium that constitutes a channel, the communication chain usually also includes an encoder and a decoder. The latter elements of the chain convert the text from one form of recording to another. It must be pointed out that the encoding and/or decoding of information may completely change the appearance of the communicated message without changing the amount of information. For example, a text written, say, in Cyrillic letters can be transmitted in Morse alphabet, which is quite different from the Cyrillic, and upon being received, it can be converted into, say, Roman characters. However, the information received is the same as the information sent, except for the unavoidable distortion caused by the noise in the channel. It can be said that information is an invariant of transliteration, which means that the set of symbols in which information is recorded can be replaced by another set of symbols without changing the amount of information in the text, provided both sets comprise the same number of available symbols. However, information is not an invariant of translation from one language to another. In such a translation, both the size of the alphabets and the lengths of text as a whole and of individual words may be different. Therefore translation changes the amount of information even if the meaningful content of the message is preserved. Information has no relation either to the semantic contents of the message or to the particular appearance of the symbols used to record it.
It is essential for our discussion to note that the more random is the transmitted text, the larger is the amount of information it carries to the receiver.
In many books on information theory one can read direct statements to the effect that information is not a synonym for meaningful content, and that information theory does not provide the means to measure or even to reveal the presence of semantic content in information.
(In a set of articles by B. McKay and myself, the study of certain statistical properties of meaningful texts as compared to randomized conglomerates of letters, a method of "Letter Serial Correlation" (LSC) and its application to a variety of texts is described. Meaningful texts display a very distinctive feature of LSC testifying to special types of order in meaningful texts, common for various languages, styles, authors, etc, but absent in meaningless conglomerates of letters. LSC is a form of statistics. It is not a part of information theory per se (even though it is related to the latter in a certain sense). Unlike the classic information theory, LSC enables one to distinguish between meaningful texts, regardless of language, authorship, style, etc, on the one hand, and gibberish in various forms, on the other. These results show very vividly the principal difference between information as defined in information theory and a meaningful message. In particular, many meaningless combinations of letters carry much more information than meaningful texts.)
In the further discussion I shall use the term "message" to always mean the meaningful contents of information. In some discussions of information, for example, by "design theorists," the distinction between information, as it is defined in information theory, and the meaningful message which may or may not be carried by information, is overlooked. This confusion is often a source of unsubstantiated assertions. In particular, if the mathematical apparatus of information theory is applied when actually not information but rather a meaningful message is under discussion, this often results in meaningless conclusions.
One of the measures of information, according to information theory, is a quantity named entropy. To all intents and purposes, it behaves like its namesake in thermodynamics. The entropy of a text quantitatively characterizes the level of disorder in that text. The more information is carried by a text, the larger is the text's entropy. The total entropy of a text as a whole is proportional to the text's length and is therefore an extensive quantity. A more interesting quantity is the specific entropy which is the entropy of a unit of text, and therefore is an intensive quantity. Usually it is expressed as entropy per character and measured in bits per character. In the following discussion, unless indicated otherwise, the term entropy will mean the specific entropy.
There exist a hierarchy of texts in regard to their entropy. For example, consider a string of the same letter (like A) repeated, say, a million times: AAAAAAAAAA... etc. This meaningless text is perfectly ordered. The entropy of that text is practically zero. Now consider a text obtained, for example, by what we can call the "urn technique." We place 27 balls, 26 of them each bearing a letter of the alphabet, and one more for space, into an urn, extract at random a ball, write down the letter found on it, return the ball to the urn, shuffle the balls, randomly extract another ball, etc. Let a text in an "urn language" be, say, a million letters long. This string is almost always gibberish. (There is some, extremely small probability that a string of an "urn language" happens to be a piece of a meaningful message.) If, as is overwhelmingly the case, this string is gibberish, in an overwhelming majority of situations there is no or very little order in that string. We call it a random string. (As Dembski correctly mentions elsewhere, there are various degrees of randomness, which is, though, irrelevant for this discussion.) The entropy of that meaningless random string is very large, and so is the information carried by that string.
Meaningful texts are located somewhere in the middle of the entropy scale, their entropy (i.e. information) being much larger than in the perfectly ordered texts of very low entropy (like AAAAAAAA...) but much smaller than in meaningless random texts.
Here are some typical numbers. The entropy of a normal English meaningful text (as was estimated already by Shannon) is about 1 bit per character. On the other hand the entropy of a text written in an "urn language," that is the entropy of a randomized sequence of 27 symbols (26 letters plus space) may be as high as 4.76 bits per character. This means the entropy of a gibberish text which conveys no message may be almost five times larger than that of a meaningful English text of the same length.
For example, in English texts the letter Q is almost always followed by U. (There may be exceptions; for example, in a paper I published many years ago about some optical phenomena, the abbreviation QE was used, which stood for Quantum Efficiency.) Therefore, if we find the letter Q in a meaningful English text, we are pretty confident that the following letter is U. Hence, when we indeed discover that the next letter is a U, it is not news. In other words, letter Q itself provides as much information as the combination of the letters QU. In a random string of characters, however, the letter Q can be followed by any letter of the alphabet, including Q itself or a space. Hence, when we find which letter follows Q in a random text, it is news for us. This means that in a random string, the combination of two letters, the first being Q, and the next one being whatever it happens to be, supplies more information than the letter Q alone. This reflects the fact that the redundancy of a meaningful text is larger than it is for random strings. The smaller the redundancy, the larger the entropy and, hence, the larger the amount of information.
(On the other hand, unlike information, Letter Serial Correlation characteristics of meaningful texts are quite different both from perfectly ordered texts of low entropy and low informational contents, and from random texts of high entropy and high informational contents.)
Let us now return to Dembski who discusses information in his books as a tool to support his "intelligent design" hypothesis.
Let us first discuss what Dembski calls "Law of conservation of information." (Recall that it is that "law" which Dembski's admirer Rob Koons proclaimed to be a revolutionary breakthrough.) Dembski indicates [2] that the name of his proposed law was used previously by Peter Medawar, whose formulation of that law was, though, in Dembski's opinion, "weaker" than Dembski's new version. Dembski's definition of the "law of conservation of information" is as follows (page 170 in "Intelligent Design"): "Natural causes are incapable of generating CSI." The abbreviation CSI stands for "complex specified information." In the further discussion Dembski abbreviates the name of the quoted law to LCI.
Without excessive modesty, Dembski claims that his "LCI has profound implications for science." A few lines further Dembski lists several "immediate corollaries," of which the first two are: "(1) The CSI in a closed system of natural causes remains constant or decreases, and (2) CSI cannot be generated spontaneously, originate endogenously or organize itself (as these terms are used in origin-of-life research.)"
There seem to be several points Dembski left without clarification. Dembski does not provide any definition of "closed system of natural causes." In particular, does Dembski include intelligent human agents into a "closed system of natural causes?" Human minds are usually viewed as "natural" but can very well generate "complex specified information," including meaningful texts. Hence, if human intelligent agents are to be included in the "closed system of natural causes," Dembski's proposed law seems to be wrong. If, though, Dembski's suggested law implies that the human mind is not natural, it would seem to be contrary to the common interpretation of the word "natural."
Likewise, we find no strict definition of the concept of CSI "complex specified information." The interpretation of that concept is of crucial importance for an analysis of Dembski's LCI. From many remarks scattered all over Dembski's writing it seems that, at least when Dembski discusses texts, he uses the expression CSI as a synonym for "meaningful content."
Here is an example illustrating Dembski's interpretation of meaningfulness of a message as a sign of specification (page 189 in "Signs of Intelligence" [5]): "A random inkblot is unspecified; a message written with ink on paper is specified. The exact message recorded may not be specified, but orthographic, syntactic, and semantic constraints will nonetheless specify it." (Note that in the case of the Voynich manuscript neither orthographic, nor syntactic or semantic data are available, but the artifactual nature of the manuscript is obvious, which is contrary to Dembski's approach.) There are many other statements in Dembski's writing indicating that he views meaningfulness of a text to be a sign of specification i.e. a sign of intelligent design.
The term "text," however, may have a very broad meaning. DNA is a text, and so is a novel or a poem, or an infinite string of digits representing the value of e, the base of natural logarithms. For example, in the collection "Signs of Intelligence," [5] of which Dembski is a co-editor, there is a paper by Patrick H. Reardon titled "The World as Text: Science, Letters, and the Recovery of Meaning." In that paper, the term text is interpreted in a very broad sense. Since Dembski is a co-editor of that collection, he probably approves of Reardon's thesis, even if only in some general way.
If such an interpretation of the term CSI is indeed correct, then a question arises: what is the word information doing in the LCI? And if the formulation of LCI includes the term "information," how to reconcile this "law" with the seminal concepts of information theory?
If Dembski's law indeed is meant to be applicable to information, as its name implies, then it cannot be applied to a text's meaningful content. If, though, the law in question is supposed to be about the meaningful message, conveyed by the text, then its name is an obvious misnomer.
Reading Dembski's treatment of information, including his alleged law, leaves the impression that when discussing CSI he does not notice how he inconsistently switches back and forth between the concepts of information in the sense of information theory and "complex specified information" which actually means a meaningful message and hence is not information in the sense of information theory. The mathematical apparatus of information theory, which Dembski uses in "The Design Inference," while may be correct in itself, is not applicable to meaningful messages, i.e. to what he refers to as CSI. In my view, this makes Dembski's entire treatment of information largely off the mark.
By calling his assertion "the law of conservation of information," Dembski apparently wished to imbue it with the significance usually associated with laws of conservation which are an important element of physics.
All of them are, of course, postulates, but, unlike the "law" suggested by Dembski, the laws of physics are postulates based on the generalization of an immense amount of observational and experimental data.
The "law of conservation of information," suggested by Dembski, despite the name given to it by that writer, is rather different from the laws of conservation in physics. Since information is neither a substance nor property, no conservation of information can be asserted. Actually the outward form of Dembski's suggested law is more similar to the 2nd law of thermodynamics. The latter states that in a closed system a quantity named entropy either remains constant or increases. The term "closed system" has a well-defined meaning in thermodynamics. A system is closed if it does not exchange energy and matter with its surrounding. However, comparing Dembski's proposed LCI with the 2nd law of thermodynamics only further undermines the former.
For example, any text, left alone, may be viewed as a "closed system" as long as no additional texts are added to it nor are any parts of it deleted. The information carried by an isolated text and measured by the text's entropy, can only increase or remain constant. Contrary to Dembski's alleged law, entropy of an isolated text cannot spontaneously decrease.
As Dembski himself correctly pointed out, with time any text left alone can only deteriorate. A certain deterioration also accompanies transmission of a text to another medium. Imagine a manuscript written on either paper, papyrus, or cloth, using, say, ink. With time, the material used for the text's recording, deteriorates. Aging of ink and of paper makes some letters change their shape so their reading becomes uncertain. For example, the original letter Q may become indistinguishable from the letter O, so whereas in the original text the following letter U was redundant, it is not redundant any longer in the deteriorated text. Hence, the deterioration of the recorded text caused the decrease of its redundancy, i.e. the increase of its entropy. What then happens to information associated with that text? Recall that the term information refers to the degree of disorder in the text. Whereas it may seem paradoxical to the uninitiated, information associated with the deteriorated texts actually increases.
A similar interpretation is applicable to information's transmission. Because of the unavoidable noise in the transmission channel, the meaningful message, if any was carried by the signal, enters the receiver partly distorted, i.e. some fraction of the meaningful message is lost. What, however, happens to information carried by the signal? It increases(if we mean information carried by a unit of text; the total amount of information can decrease if parts of the text are completely obliterated thus decreasing the overall length of the text). The disorder in the transmitted message increases because of noise, so its redundancy drops, while its entropy, i.e. the information associated with a unit of that text, increases. (The above description is true only if the transmitted text is not perfectly random. The specific entropy of a perfectly random text has the maximum possible value for example 4.76 bits per character for a random conglomerate of 27 symbols and cannot increase; if such a random text is transmitted, the noise does not increase its specific entropy any more, but it does not decrease it either. The specific entropy of an isolated random string is conserved.)
Recall now our earlier discussion of Dembski's inconsistent use of the term "agency" vs "design" as well as of what I denoted as various degrees of design, and various degrees of specification. When dealing with human design, we have no problem of identifying design, regardless of the "degree of specification." However in the case of a supposed supernatural design our requirements for identifying design must necessarily be much more stringent. Imagine that we generate a random string of letters using the "urn technique," described earlier. If we create a long string of letters by using that technique, we will confidently attribute the creation of a random string of letters to human design, since we realize humans had to make the balls and the urn, to place the balls in the urn, to pull balls out one by one, to write down the letters, and the random string could not be created spontaneously without the described deliberate actions by humans. Indeed, the string of gibberish in Behe's example was actually deliberately created by him as an example. However, in order to attribute an event to supernatural design, we justifiably demand more a string of letters must be specified in a much stronger way to infer supernatural design. The reason for that is the simple fact that stochastic processes which occur without a human or a direct supernatural interference are capable of creating information-rich structures.
As we discussed earlier, Dembski seems to view the meaningfulness of a string of letters as a necessary feature for inferring design. Since Dembski seems to view meaningful contents as a necessary component of specification, then, to be consistent, he should apply this requirement to biological structures as well as he does it to strings of letters.
In section 6.5 of "The Design Inference" Dembski estimates the so-called "universal probability bound," which he suggests to be at pm=½ . 10-150. This number allegedly indicates the minimum value of the probability of an event that can occur by chance. If the probability of an event, estimated assuming it happened by chance, is less than pm, then its occurrence necessarily must be attributed to design. On page 166 of his other book, "Intelligent Design," Dembski again gives the same value for the "universal probability bound," and elaborates by indicating that "the probability bound of 10-150 translates into 500 bits of information. Accordingly, "specified information of complexity larger than 500 bits cannot reasonably be attributed to chance."
This is an example of Dembski's inconsistency. In the first of the quoted sentences he speaks about "information." He is correct in stating that a probability of 10-150 translates into about 500 bits of information. In the next sentence he replaces the term "information" with "specified information," i.e. with a different concept, which actually seems to mean a meaningful message.
To be consistent, Dembski had to speak either about information, or about "specified information," rather than surreptitiously replacing one with the other.
If we want to discuss information, then Dembski's assertion that in case its size is above 500 bits it cannot be attributed to chance, is, in my view, wrong. Indeed, any random string containing, for example, more than 105 letters of English alphabet (26 different letters plus space) carries over 500 bits of information. It can be easily obtained by chance. For example, recall the "urn procedure," described earlier. Instead of pulling out the balls by hand, we can do it in a way utilized in the Keno game played in Las Vegas casinos. In those casinos, a machine is used which constantly shuffles the balls, randomly pushing out ball after ball, each ball bearing a certain number. If instead of numbers, such balls bear letters, the machine can generate a random text of any length. In such a text, the design by a human agent is only limited to creating conditions (designing a machine) which would effect a random procedure. As soon as the text has more than 105 randomly chosen letters, it carries over 500 bits of information, and every particular string obtained this way is the result of a chance procedure. Therefore, Dembski's "universal probability bound," or its reincarnation in the "universal complexity bound" is irrelevant as long as information per se is in question.
"Specified information" is a very different animal. This term, in Dembski's usage, seems to denote a meaningful message. The latter is not measured in bits, and cannot be at all treated using methods and mathematical apparatus of information theory. Any random text carries much more information (in the sense of information theory) than any meaningful text of the same length. To judge the probability of a chance emergence of a meaningful text by applying information theory is like measuring the sweetness of ice cream by the brightness of colors on its label.
If we see a novel, or a poem, we certainly know it is a meaningful message. Our knowledge is based on our ken, including our experience with messages stemming from the human intelligence. There is nothing like that in biological structures, which are often enormously complex, but have never been shown to carry a meaningful message. System of any complexity can emerge as a result of a stochastic process, without carrying any meaningful message. If we continue the mechanical procedure of randomly pushing letter-bearing balls out of an urn, the recorded string of letters will become more and more complex. If the machine kicks out balls, say, a little more than 1000 times, the information in the ensuing random string will soon exceed 5000 bits, which translates into probability of 10-1431, i.e. immensely lower than Dembski's "universal probability bound" of 10-150.
Again, let us agree that if a not very short text carries a message, this points, with overwhelming probability, to an intelligent author (although there always is a very small, but non-zero probability that the message is an accidental outcome of random events). Information, on the other hand, is indifferent to the message and therefore cannot itself point to an intelligent source. In particular, DNA obviously carries information but there is no way to assert that it carries a message. Indeed, how can Dembski determine whether or not the information in DNA is specified? It is just an unsubstantiated assumption. The available data about the structure of DNA indicate that the DNA strand consists both of pieces of a genetic code, and of segments which do not seem to carry any genetic code.
Here is a quotation from an article [12] by the prominent biologist Kenneth R. Miller, who, by the way, is a Christian believer: "In fact, the human genome is littered with pseudogenes, gene fragments, 'orphaned' genes, 'junk' DNA, and so many repeated copies of pointless DNA sequences that it cannot be attributed to anything that resembles intelligent design. If the DNA of a human being or any other organism resembled a carefully constructed computer program, with neatly arranged and logically structured modules, each written to fulfill a specific function, the evidence of intelligent design would be overwhelming. In fact, the genome resembles nothing so much as a hodgepodge of borrowed, copied, mutated, and discarded sequences and commands that has been cobbled together by millions of years of trial and error against the relentless test of survival. It works, and it works brilliantly; not because of intelligent design, but because of the great blind power of natural selection to innovate, to test, and to discard what fails in favor of what succeeds. The organisms that remain alive today, ourselves included, are evolution's great successes."
Let us compare DNA strand to a string of letters. If such a string is not very short and is a meaningful text (for example, a poem or a novel), the probability of its being the result of chance is indeed exceedingly small. Let us now recall the example discussed both by Dembski and Behe. In that example, two strings of Scrabble letters are compared, one being a piece of gibberish and the other a phrase from Hamlet. As Dembski and Behe asserted, the string of gibberish must be attributed to chance, because it is not specified (i.e. is not a recognizable meaningful text.) Let us now look at the following string of letters:
"prsdembkreddnpljassddskipqooppppazxkhmainwcloyyrfh
lklktains
yuuklscvmwwthatooedflllmqdcompjertfffvaqpurcl
exitystolmjdgesetgbd
koqpmzfyhntogetsqoprthjncdeherabpuu
erthhhwitherimnaderlthhjkkspecif
herrvuiwplkxqcghkricationiiieklodsg
..."
Isn't the above string gibberish? Obviously it is. Hence, according to the criteria suggested by Dembski and Behe, its creation must be attributed to chance. However, if one carefully reads that string letter by letter, one can discover in it, within the gibberish, meaningful segments, which read: "Demb... ski... main... tains... that... comp... lexity... toget... her... with... specif...ication..."
Even if we apply Dembski's criterion which bases the identification of a designed text on the latter's meaningfulness, having discovered the islands of a meaningful text within the above meaningless string will hardly lead us to the conclusion that the string was deliberately designed. A more plausible interpretation seems to be that the meaningful segments happen to occur within gibberish by chance alone. (Of course, I have deliberately created that string in order to provide an illustration of my thesis. However, Behe and Dembski have created their strings of gibberish the same way. Their example implied that the strings of letters were found by accident and their origin was unknown. I have simply followed their way of discussion.) The farthest we may go is to infer that somebody took time to use, say, an "urn technique" or some alternative method of creating this string, and only in that sense the string was designed. However, we will have little reason to see in that string a meaningful message rather than gibberish. The longer the pieces of gibberish and the larger their number in the string, the more will it look like a random string which contains segments of a seemingly meaningful text by sheer chance. As biologists tell us, DNA looks much more like the latter example than like the text of a poem or a novel. Moreover, in the above string the seemingly meaningful segments are readily recognizable as those of English text (in Dembski's terms, their patterns are "detachable") whereas in a DNA strand even the segments that serve as genes are revealed to be such only via special investigation and are not immediately recognizable, i.e. not "detachable," and hence not really "specified" in Dembski's terms. Moreover, strings of letters are incapable of reproduction on their own, hence, unlike biological structures, they could not have evolved from some other, simpler strings.
Of course, as any analogy, the above example of gibberish with accidental chunks of meaningful English words is not an exact representation of a DNA strand. The latter has many features which are absent in the above text. This example only illustrates my thesis and is not intended to serve as a proof of that thesis.
However, I believe that the biological structures seem to better conform to the hypothesis that they emerged as a result of random events than as a result of intelligent design (of course, according to the Darwinian theories, the process of the emergence of biological strands such as DNA has also included non-random steps such as natural selection which is not random.) The assertion that DNA complexity is "specified" and therefore points to design, has so far no foundation in known facts.
Some creationists, both among those openly admitting being creationists and among those protesting against such label, adhere to a preposterous notion that "chance cannot create information" (see, for example books by P. Johnson or L. Spetner). Since biological structures, such as DNA, RNA or proteins all carry a lot of information, these creationists argue that this very fact testifies that life could not develop without an "intelligent agent" (which usually is just a code-word for the biblical God).
Unlike some of his colleagues, Dembski admits that chance can create information. Moreover, he even admits that chance can create complex information and that chance can create specified information. What chance cannot create, claims Dembski, is information which is both complex and specified. In this claim, Dembski implicitly performs a sleight-of-hand. While saying "complex specified information," he actually seems to mean a meaningful message. Yes, the probability of a meaningful message emerging by chance is extremely small, but this by no means applies to information, however complex and "specified" the latter may be. Plenty of information can be (and routinely is) generated in stochastic processes. In some sense, such information may be "specified" and complex, even if it carries no meaningful message.
The enormous amount of
information in biological structures does not in itself contradict the
hypothesis of a spontaneous emergence of life. To prove otherwise, "design theorists" would need a different type of
argument. So far their "theory"
is little more than an arbitrary hypothesis. Dembski's treatment of information does not, in my view, add anything
of substance to the dispute in question.
7. Dembski's design inference
The main conclusion of Dembski's entire discourse is what he calls "the design inference." This concept has been rendered by Dembski in several versions, both in plain words and in a mathematically symbolic form. Let us look once again at the design inference according to Dembski (page 48 in "the Design Inference"):
Premise 1: E has occurred.
Premise 2: E is specified.
Premise 3: If E is due to chance, then E has small probability.
Premise 4: Specified events of small probability do not occur by chance.
Premise 5: E is not due to regularity.
Premise 6: E is due either to a regularity, chance or design.
Conclusion: E is due to design.
A crucial element of the above argument is premise 4, which constitutes what Dembski calls the Law of Small Probability: "Specified events of small probability do not occur by chance."
Without that "law" the entire argument would collapse.
I submit that the "law" in question is logically deficient. The reason for that conclusion is as follows. In that sentence two concepts specification and low probability - are presented as two independent categories. However, I believe that an event is commonly judged as having low probability because specification is just one of the factors which contributed to the low estimate of probability.
For the sake of further discussion, I will adopt a broader definition of specification, not as a substitute for Dembski's definition when design inference is at stake, but only to identify a certain feature of specification which is relevant to my discussion. My provisional broader definition of specification is based on the common interpretation of that term. I suggest that selecting for consideration a particular pattern or event out of the multitude of possible patterns or events makes it specified, and this, in my view, is the most all-embracing definition of specification. Dembski's definition is narrower than the one I offer, but obviously all patterns/events which meet his definition also meet my definition, although the opposite is not true. All events/patterns that meet Dembski's definition constitute a subset of a larger set which comprises all events/patterns that meet my broader definition.
Let us denote specification in a broader sense, according to my definition, as b-specification, and specification according to Dembski as d-specification.
I submit that one of the properties inherent in all events/patterns that meet my broader definition is that b-specification necessarily decreases the estimate of an event's probability, and therefore also for every event/pattern that meets Dembski's definition, d-specification decreases the estimate of the event's probability as well.
As an example, consider a game in which there are two players. Player A has in his pocket a one-dollar bill and player B has to guess what is the number on that bill. Let say, the number is L14142983Q. It is "specified" in that it is a specific number which is unequivocally distinguished from any other number, constitutes a recognizable pattern according to Dembski's criterion, and therefore meets his definition of specification (i.e. of detachability and delimitation.) Of course in this particular case, it meets my broader definition as well. Obviously the probability of player B correctly guessing the number in question is very small.
Now, imagine that we have to deal with "fabrication" according to Dembski's concept. It means that player B does not guess the number in question before seeing the bill, but first looks at the bill and then announces the number on that bill. Obviously, now the event, which is "fabricated" rather than "specified," has the probability of 100%.
What made the probability of this event in the first case much smaller was its specification.
The above discussion does not imply that all specified events have low probability in absolute terms. What is viewed as a small probability in a certain situation, may be viewed as not a very small probability in some other situation. Certainly many specified events can have a relatively large probability. For example, consider a game in which players guess which card has been pulled at random from a deck of 52 cards, before the card is actually seen. Since the deck comprises 52 cards, the probability that the chosen card will happen to be, say, seven of spades, is one in 52, which is not really small. "Seven of spades" constitutes b-specification. If the card has not been specified, the probability that the chosen card will happen to be one of the 52 possibilities, is 100%. The probability of choosing at random a specified card, while not very low (one in 52) is though 52 times less than in case the card was not specified. Specification makes probability relatively small, as compared with the absence of specification. An estimate of probability is meaningful only in terms of relative values.
Let us take one more look at the example given by Behe in his foreword to Dembski's "Intelligent Design." Recall that in that example, we find a string of Scrabble letters, in one case spelling a meaningful English phrase and in the other, a meaningless sequence. The probability of the appearance of either of these sequences by chance is, according to Dembski, equally low. However, in Dembski's interpretation, the first sequence is specified whereas the second is not. As I have suggested earlier, a more reasonable approach seems to view both sequences not only as having equally small probabilities, but also as being specified, but to a different degree. Indeed, according to my, broader definition of specification, as soon as any of these two sequences has been chosen, it has been specified, regardless of its being meaningful or meaningless. To see why the latter approach seems to be reasonable, imagine that we obtain the meaningless sequence using the "urn technique," continuing the procedure until we have a sequence of N letters written down. If N>105, the probability of a particular sequence to appear is p<10-150. However, the probability that some unspecified sequence will appear as a result of the described procedure is of course 100% (p=1.) Hence, if we b-specify the sequence, this drastically decreases the estimate of probability. It does not matter whether the b-specified sequence is meaningful or not.
Specification according to my definition (b-specification) is not equivalent to meaningfulness.
The difference between the two sequences in Behe's example is not in that one is specified while the other is not. Both have been b-specified by the action of Behe who chose them for his example (actually he had deliberately created the meaningless sequence as an example.) The probability of the two sequences emerging by chance was equally small, the small probability being due to the b-specification the choice of those specific sequences for consideration. An unspecified sequence is that which has not been specifically chosen and, hence, is undefined (unknown.)
(This assertion is also closely connected to the difference between information and semantic contents of a message, which was discussed in the section on information.)
If an objection is offered maintaining that the meaningless string does not meet Dembski's definition of specification (I am not delving here into the discussion of such an objection) it does not matter for our discussion whether or not such an objection is correct. The assertion that specification of a pattern decreases the probability of an event remains valid because any pattern that meets Dembski's condition of specification, belongs to a subset of a wider set meeting my definition. Any specification, whether or not it meets Dembski's definition, decreases the probability of the event in question.
A similar situation exists in the case of a raffle. If there are, say, ten million tickets sold, the probability of a specified ticket winning is one in ten million. However, the probability of some unspecified ticket winning is 100% (p=1.) What made the probability of a particular ticket winning so much smaller was b-specification the choice of a particular ticket. Obviously, it has nothing to do with any meaningfulness of the choice.
Therefore the Law of Small Probability in Dembski's rendition which regards probability and specification as two independent categories is, in my view, logically flawed.
Dembski's effort to define the features of legitimate specification, such as detachability (and its constituents - conditional independence of side information and tractability) and delimitation, are unnecessary complications which actually seem to be aimed at distinguishing meaningful specified structures from meaningless ones (although Dembski nowhere mentions directly that distinction.) However, from the above examples it seems that his convoluted discourse did not achieve its goal. The difference between a meaningful message and a simply information-rich structure remained elusive no less than before Dembski's exercise. (The modern development of information theory, in particular that based on the concepts of the algorithmic theory of probability/complexity, features some substantial advances toward the distinction between noise and "meaningful information" see, for example [13]; this development goes however well beyond Dembski's discourse).
From another angle, if we recall the procedure prescribed by Dembski for the third "node" of his explanatory filter, we see that the probability of the tested event is estimated in that "node" assuming that the event occurred by chance. If that is the case, then it seems to me that instead of saying "Specified events of low probability do not occur by chance," Dembski should have said: "specified events, whose probability estimated upon the assumption that they occurred by chance, turns out to be low, do no occur by chance." Since Dembski has not spelled it this way, we have to discuss his law in the form it has been offered.
If the estimation of probability is made assuming chance, then, since law has been already excluded, the adopted assumption predetermines relatively low probability. We estimate the probability to be low by first assuming that it is relatively low.
By mentioning "specified events" Dembski actually has already chosen events whose probability is relatively low because of specification, so the phrase "specified event of low probability" really means "events of relatively low probability which have low probability." The formula of Dembski's law seems therefore to actually mean: "Events of relatively low probability whose probability is low do not occur by chance." I am sorry if this sounds like a parody.
I submit that Dembski's law of small probability makes little sense in that it does not really shed light on the problem of identifying design. No mathematical symbolism, with all of its sophisticated appearance, can save the law in question from being a platitude.
(Of course, as was discussed earlier, and contrary to Dembski's scheme, specification is only one among a multitude of factors which affect the estimated value of probability.)
Look at it once again, this time in its particular form, found on page 56 in "The Design Inference:"
Premise 1: LIFE has occurred.
Premise 2: LIFE is specified.
Premise 3: If LIFE is due to chance, then LIFE has small probability.
Premise 4: Specified events of small probability do not occur by chance.
Premise 5: LIFE is not due to regularity.
Premise 6: LIFE is due either to a regularity, chance or design.
Conclusion: LIFE is due to design.
I have serious doubts about the validity of some of those premises.
Premise 1 meets no objection since it is simply a statement of fact. However, the rest of the premises sound dubious in some respects.
Start with Premise 2 "LIFE is specified." The question here is what is the meaning of the term "specified" as applied to LIFE. Specification is the choice of a certain event or object from among a number of alternatives, whatever definition of specification one adheres to, including Dembski's own. If he means, for example, specification on a biochemical (molecular) level, then, if we define specification simply as stemming from the rich informational contents of biological structures, premise 2 may be provisionally accepted. However, as discussed in this article, rich informational content is not at all equivalent to a meaningful message. Recall that Dembski views meaningfulness as the feature which defines a string of letters as having resulted from design. To be consistent, he must require at least as much from a biological structure in order to attribute it to intelligent design, even if we may not be able to decipher the meaning stemming from a supernatural intelligence.
Premise 3 if LIFE is due to chance, then LIFE has small probability - seems to be a hypothesis whose validity is not at all clear. First, regardless of the question of LIFE's origin, chance events may have a large probability. If we toss a coin, the probability of tails is ½ which is by no means a small probability. The outcome of tails is, though, obviously a chance event. Assigning a small probability to an event simply because it has occurred by chance, as this premise seems to be formulated, is a dubious proposition. Regarding this premise in its specific application to LIFE, it is a hypothesis which may be correct but may be also wrong. There are well known theories based on the opposite premise, allowing for the possibility that the spontaneous emergence of life had a rather large probability.
Premise 4 is the Law of Small Probability, whose logical deficiency has already been discussed.
Premise 5 LIFE is not due to regularity is a hypothesis, which may be true, but has not been proven. This premise actually is in some sense equivalent to premise 3 if a certain regularity was responsible for the emergence of LIFE, this is tantamount to the assertion that the emergence of LIFE was rather likely. The possibility of life having emerged due to a regularity, as some scientists believe may be the case, has not been categorically excluded by any uncontroversial arguments (see, for example, Jigsaw model of the origin of life which offers a plausible mechanism for the spontaneous emergence of life wherein the probability is immensely larger than for a pure chance and which can possibly be explored under laboratory conditions.)
Premise 6 life can be attributed only to any one of the three possibilities - is also a hypothesis. The origin of life as a result of a superimposition of more than one of the three listed causal factors cannot be excluded.
Hence, the conclusion in the above argument, that LIFE is due to design, is, in my view, based on one statement of fact, three unproved hypotheses, one more or less plausible premise, and one logically deficient statement. Of course, the weakness of the above seven-step argument does not mean that its conclusion is necessarily wrong. It may be true, but it requires a much more consistent and unequivocal set of arguments. As the matter stands now, Dembski's argument, in my view, is far from convincing.
As I have stated before, there was no way for me to offer a comprehensive review of Dembski's two books and several papers in one article of a reasonable length. For example, I have left out of consideration those two parts of "Intelligent Design," in which Dembski discusses the historical development of the design concept (part1) and "bridging science and theology" (part 3), as well as some other parts of his books and papers. I have concentrated on the most salient points of what Dembski calls his "Theory of Design."
My review may seem to have been conducted from several standpoints. This was due to the numerous inconsistencies in Dembski's discourse, which required me to shift my position in order to get the perspective on various deficiencies in that discourse. My task, however, was not to suggest an alternative, consistent theory of design, or to repair Dembski's theory (which, in my view, is beyond repair) but to unearth the jumps over pits in logic which are found in Dembski's production.
Let me briefly summarize the main elements of my critical review.
Formulating his concept of design, Dembski suggests that the latter is not a causal but a logical category, and that design does not necessarily entail a designer. However, contrary to that notion, he often refers to design as a synonym for agency, having defined the latter as a conscious activity of an intelligent agent.
Having defined design as simply the exclusion of regularity and chance, he often forgets about his own definition and refers to design as an independently defined category.
The "law of small probability," suggested by Dembski as one of the main pillars of his theory of design, seems to be intrinsically contradictory in that it fails to recognize the probabilistic character of design inference and artificially separates probability from specification.
The "law of conservation of information" suggested by Dembski, first, seems to imply that human intelligence is not natural, and, second, contradicts some fundamentals of information theory and therefore makes no sense.
Of the three "nodes" of Dembski's explanatory filter, the first two play no useful role, as they imply an unrealistic procedure of estimating probability prior to assuming chance or regularity as the event's causes.
The explanatory filter as a whole, which seems to be the heart of Dembski's theory, produces both false negatives (as Dembski admits) and false positives (which is contrary to Dembski's assertion.)
Dembski's categorical demarcation between law, chance and design, as three independent causes, does not seem to be realistic either, as it ignores multiple situations wherein either two or all three causes may be at play simultaneously. His scheme ignores many situations where the causal history of events is complicated by feedbacks, conditional causes etc.
The versions of probability theory and complexity theory suggested by Dembski do not seem to make much sense either. His definitions of probability, likelihood, complexity, and difficulty lack any indications of how to choose the quantities which are necessary parts of those definitions. Besides, his definitions of complexity and difficulty, while they may be relevant for some particular situations, are unduly generalized as supposedly having universal applicability. There are many classes of events wherein his definitions are contrary to the actual situations.
Dembski's theory does not recognize the differences between human, alien and supernatural types of design, which is arguably the most interesting problem (not to mention the problem of design by artificial intelligence.)
Contrary to Dembski's scheme, it was demonstrated that sometimes design can be reliably inferred in the absence of a recognizable pattern, i.e. of specification, while in some other cases specification does not ensure the reliability of design inference. He elevated specification, i.e. a recognizable pattern, to a unique status among all possible factors which affect the design inference, without any justification for such a preference.
Therefore the conclusion seems to be that Dembski's entire explanatory scheme is built on sand.
The design inference argument, utilized by Dembski to conclude that LIFE is due to design, includes a number of arbitrary assumptions and logically deficient assertions and therefore lacks evidentiary value.
This list of inconsistencies and weaknesses can be extended, as it was discussed in detail in this paper.
While I am of the opinion that Dembski's effort to create a consistent theory of design failed, I cannot assert that the hypothesis of intelligent design itself is wrong, but only that neither Dembski nor any of his co-believers have so far succeeded in proving it.
While on the cover of Dembski's book "Intelligent Design" we find a series of quotations from a number of his admirers, his more mathematically loaded book "The Design Inference," as fits the publishing practice of the Cambridge University, contains only one, short introduction by the mathematician David Berlinski, known as an uncompromising adversary of Darwinism. Berlinski writes, among other things, about Dembski's book, that "It is a fine contribution to analysis, clear, sober, informed, mathematically sophisticated and modest."
The first ("fine contribution") and the second ("clear") points in Berlinski's six-point evaluation are a matter of personal opinion, so I will not argue against them.
Regarding the third point ("sober"), I don't know what Berlinski meant by that term. If he used it as a synonym for "reasonable," I would only accept it with reservation. As can be seen from the preceding sections, in my view, many parts of Dembski's discourse make no sense. Apparently, that view, at least to a certain extent, is shared, among many others, by Chiprout, Eells, Elsberry, Fitelson, Korthof, Pennock, Pigliuccci, Ratzsch, Schneider, Sober and Stephens.
Regarding Berlinski's fourth point ("informed"), I fully agree with it if it means that Dembski is well educated and possesses a wide knowledge of various subjects and topics. Yes, Dembski's writing indeed testifies to his extensive background in various fields of knowledge, including philosophy, theology and mathematics.
Regarding Berlinski's fifth point ("mathematically sophisticated"), again, the question is what is the meaning of that term. If Dembski's mathematical sophistication is supposed to mean that he has a good understanding of various fields of mathematics, is comfortable with mathematical symbolism, and knows how to apply various mathematical concepts, I would agree with Berlinski's assessment. However, if the term in question implies that Dembski's work constitutes an innovative contribution to mathematics or to its application in some field, in my view this assertion would be hardly justified. Some parts of Dembski's mathematical exercise, while rather sophisticated and well thought through and even interesting by themselves, (for example, all the material on pages 122-135 or 209 213 in "The Design Inference") seem to be not germane to his theme. Dembski discusses there in minute detail certain topics rather extraneous to his main thesis. On the other hand, some parts of his mathematical exercise (for example his treatment of probability and likelihood) in my view do not meet the requirements for a rigorous mathematical discourse.
Berlinski's final point ("modest") seems to be quite off the mark. Dembski's style reveals his feelings of self-importance, which is obvious not only from his penchant for introducing pompously named "laws" but also from his categorically claimed conclusions and such estimates of his own results as calling some of them "crucial insight," "profoundly important for science," or "having a huge advantage" over existing concepts.
Then, in the few replies to his critics which Dembski deigned to provide, his main thesis seems to be that his critics simply do not understand his fine discourse. This method of discussion hardly seems to meet the concept of modesty. It reminds me of the story about a detachment of soldiers in a boot camp. When a sergeant reproached a soldier for walking out of step with the rest of the platoon, the soldier replied that it was he who walked in step, while all the rest of the soldiers walked out of step.
Of course, Dembski is a well educated and very intelligent writer. No doubt he has many talents and is quite capable of achieving significant results in various fields of science. I believe it is regrettable that he has been wasting his talents on attempts to create a revolutionary theory in one fast move, instead of engaging in a decent scientific research with its gradual and painstaking accumulation of knowledge.
A good scientific work includes as a necessary part relentless attempts by the scientist himself to find the most powerful arguments which would disprove his conclusions. Dembski seems to have failed to perform such a self-check. The result was a seemingly very sophisticated theory, which may be impressive to those who find in it a confirmation of their already held convictions but which has many holes and inconsistencies.
While predicting the future is always a very unrewarding job, I have a feeling that the absence of supernatural intelligent design will never be proven because, I suspect, it is impossible to prove. I don't know whether it is possible or not to prove the existence of a supernatural intelligence. So far it does not seem to have happened. Dembski's books and papers do not seem to have changed this situation.
[1] William A. Dembski, The Design Inference, Cambridge University Press, 1998.
[2] W. A. Dembski, Intelligent Design, InterVarsity Press, 1999.
[3] W.A. Dembski, ed., Mere Creation, InterVarsity Press, 1998.
[4] M.J. Behe, W.A. Dembski and S. C. Meyer, eds., Science and Evidence for Design in the Universe, Ignatius Press, 2000.
[5] W.A. Dembski and J. M. Kushiner, eds., Signs of Intelligence, Brazos Press, 2001.
[6] Robert T. Pennock, Tower of Babel, The MIT Press, 2000.
[7] Del Ratzsch, Nature, Design and Science, State University of New York Press, 2001.
[8] Ellery Eells, Philosophical Books, v.40, No 4, 1999.
[9] Branden Fitelson, Christopher Stephens and Elliott Sober, Philosophy of Science, v.66, pp. 472-488, 1999.
[10] Massimo Pigliucci, BioScience, v. 50, No 1, 2000.
[11] Massimo Pigliucci, Skeptical Inquirer, September-October 2001.
[12] Kenneth R. Miller, Technology Review, v..97, No 2, pp. 24-32, 1994.
[13] Paul Vitanyi, Meaningful information - in Front for the Mathematics ArXiv.